立体视觉综述:Stereo Vision Overview
本文主要翻译自Mattoccia的双目视差估计综述,对于刚刚接触立体深度估计方向的小伙伴会有帮助;如果你是专家也可以做一下复习,如有错误请在评论中指出。
文中主要介绍以下几个方面的内容:
- Introduction to stereo vision
- Overview of a stereo vision system
- Algorithms for visual correspondence
- Computational optimizations
- Hardware implementation
- Applications

什么是立体视觉
- 是一个能够从双目或者多目相机中提取深度图像的技术
- 在计算机视觉领域很火爆的研究话题
- 这与以下几个方面的相关:双目立体视觉系统、稠密立体算法、立体视觉应用
- 偏好能够实时或者硬件实现
单目相机
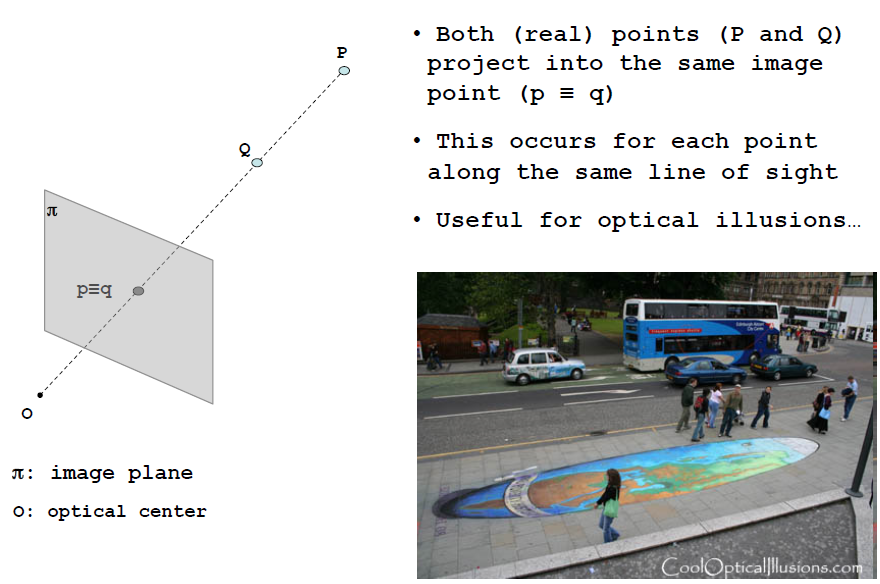
如图所示的是单目摄像机的拍摄原理,右侧实际场景可以抽象成左侧的模型。可以发现场景中的P点与Q点会同时汇聚在成像平面中的一点,同样遮挡问题出现在PQ连线的所有点。
双目相机
对于双目相机,和分别是左右相机的光学中心,对于在参考相机像平面上被汇聚的两点(p和q),在目标相机像平面上会被区分开来,那么我们可以找到双目或者多目相机中匹配的点利用三角相似原理来估计深度。那么我们怎么寻找相对应的点呢?一个直观的想法就是固定两幅图中的一幅,然后在另外一幅图中 进行2D范围的搜索匹配点。 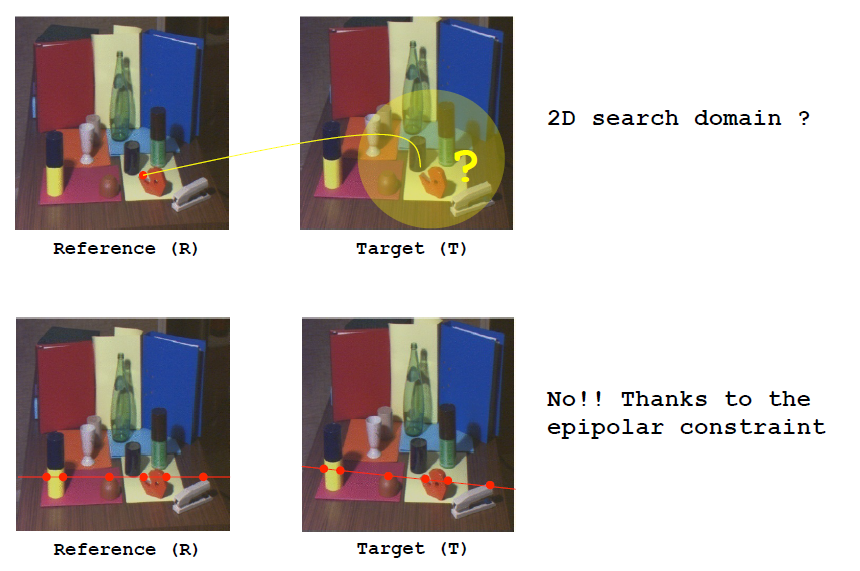
但实际情况这样做的代价非常大。不过多亏了有极线约束,我们可以在图像的1D范围上进行搜索。以下将要对极线约束进行解释。
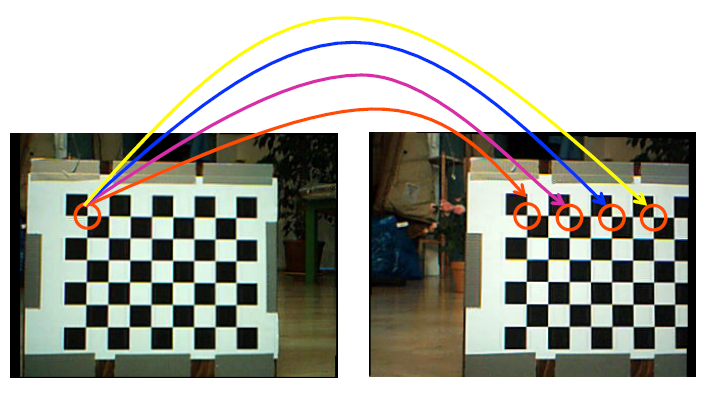
极线约束(对极几何)
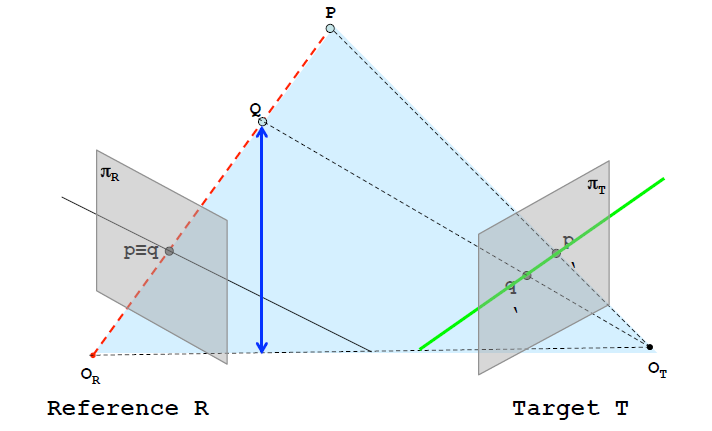 - 对于参考图像R而言,现实场景中的P与Q点在其像平面上被投影成为一个点p=q。 - 极线约束规定,属于(红色)视线的点对应位于目标图像T的图像平面上的绿线上。
- 对于参考图像R而言,现实场景中的P与Q点在其像平面上被投影成为一个点p=q。 - 极线约束规定,属于(红色)视线的点对应位于目标图像T的图像平面上的绿线上。
我们可以在维基百科上找到更为详细的介绍,具体描述可见下图。特别感谢@岳麓吹雪同学的帮忙,以下是他已经整理好的译文。下图是针孔相机模型图。两个针孔相机看向空间点,实际相机的像面位于焦点中心后面,生成了一幅关于透镜的焦点中心对称的图像。这个问题可以简化为在焦点中心前方放置一个虚拟像面来生成正立图像,而不需要对称变换得到。和表示两个相机透镜中心,表示两个相机共同的目标点,和是点在两像面上的投影。 
-
epipolar points极点 每一个相机的透镜中心是不同的,会投射到另一个相机像面的不同点上。这两个像点用和表示,被称为epipolar points极点。两个极点、分别与透镜中心、在空间中位于一条直线上。
-
epipolar plane极面 将、和三点形成的面称为epipolar plane极面。
-
epipolar line极线 直线被左侧相机看做一个点,因为它和透镜中心位于一条线上。然而,从右相机看直线,则是像面上的一条线直线,被称为epipolar line极线。从另一个角度看,极面与相机像面相交形成极线。极线是3D空间中点X的位置函数,随变化,两幅图像会生成一组极线。直线通过透镜中心,右像面中对应的极线必然通过极点。一幅图像中的所有极线包含了该图像的所有极点。实际上,任意一条包含极点的线都是由空间中某一点推导出的一条极线。
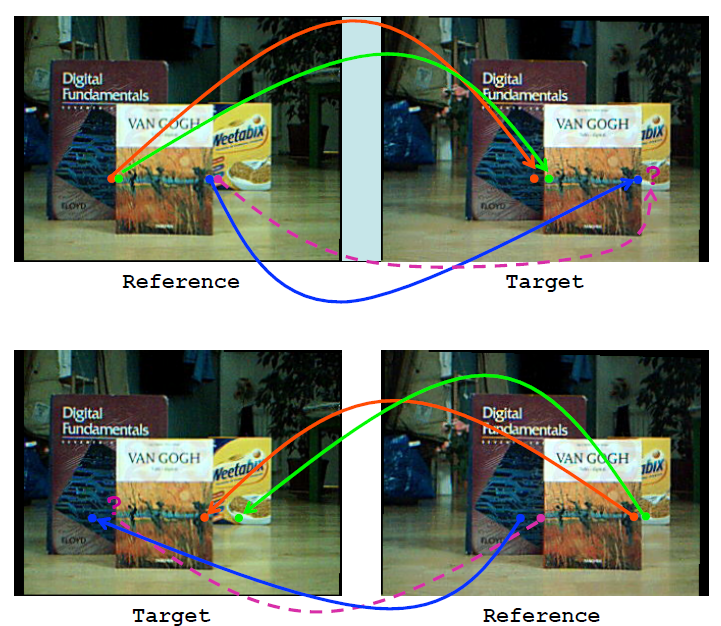
如果两个相机位置已知,则: 1.如果投影点已知,则极线已知,点X必定投影到右像面极线上的处。这就意味着,在一个图像中观察到的每个点,在已知的极线上观察到该点的其他图像。这就是Epipolar constraint极线约束:在右像面上的投影必然被约束在极线上。对于上的,,,都受该约束。极线约束可以用于测试两点是否对应同一3D点。极线约束也可以用两相机间的基本矩阵来描述。 2.如果和已知,他们的投影线已知。如果两幅图像上的点对应同一点X,则投影线必然交于。这就意味着可以用两个像点的坐标计算得到。
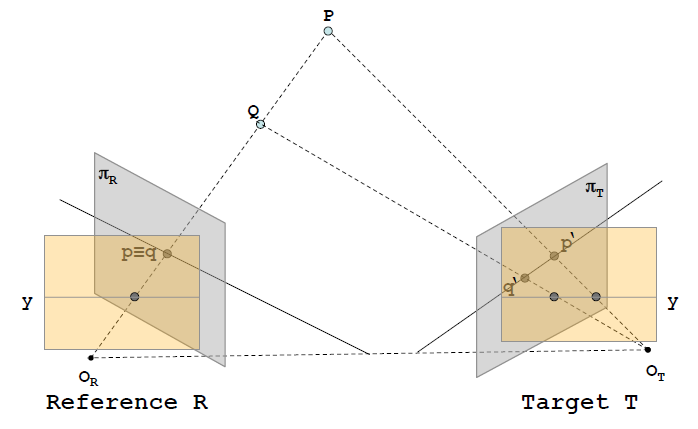 由极线约束可知,我们可以将原来的匹配点搜索范围由2D转换成1D,这样做可以很大程度上减少计算量。我们将左右视图摆放成更容易理解的形式,可以发现对应点的匹配问题转换成了在同一条扫描线上(极线)的匹配问题。
由极线约束可知,我们可以将原来的匹配点搜索范围由2D转换成1D,这样做可以很大程度上减少计算量。我们将左右视图摆放成更容易理解的形式,可以发现对应点的匹配问题转换成了在同一条扫描线上(极线)的匹配问题。
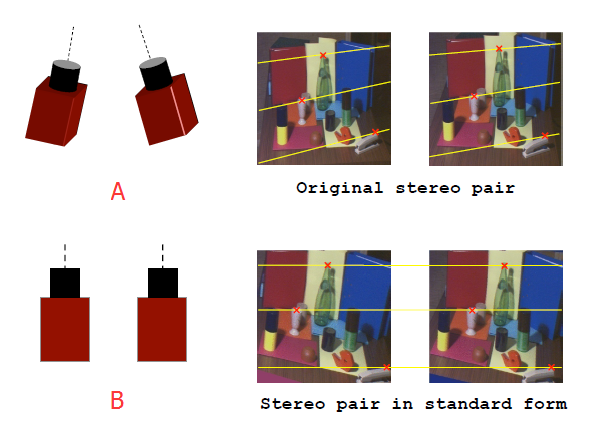 可以发现相机的摆放姿势影响着扫描线的方向。在上图A中,相机与水平呈一定角度地摆放,其扫描线为右图所示,同样是与水平倾斜的扫描线。假如两个相机平行摆放的话,其拍出来匹配对是扫描线已经对齐了的。
可以发现相机的摆放姿势影响着扫描线的方向。在上图A中,相机与水平呈一定角度地摆放,其扫描线为右图所示,同样是与水平倾斜的扫描线。假如两个相机平行摆放的话,其拍出来匹配对是扫描线已经对齐了的。
深度与视差
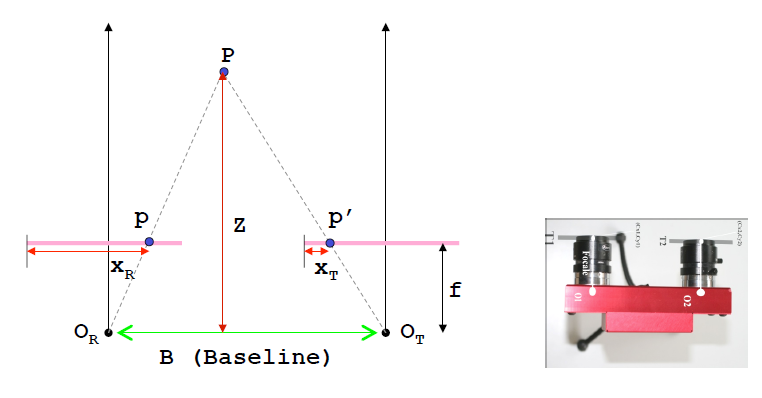 如上图所示为扫描线已经对齐了的匹配图像对(以下简称匹配对)。可以发现:与是相似三角形,由于相似三角形原理,我们可以很容易知道:
如上图所示为扫描线已经对齐了的匹配图像对(以下简称匹配对)。可以发现:与是相似三角形,由于相似三角形原理,我们可以很容易知道:
所谓视差就是匹配对中对应点之间x方向上的差异,我们可以将这种差异转换成为灰度图(越近越白),如上最后一个图所示。 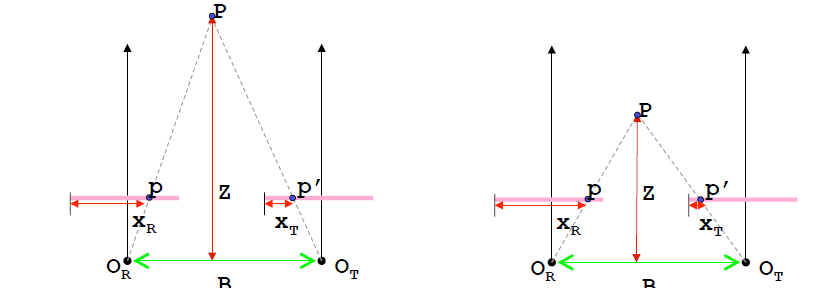
上图展示了物体距离相机越近的话,视差就越大。其实很容易理解,将人的双眼比作成双目相机,对比将手指放在双眼前方近处与远处晃动的区别,可以发现在近处的话人眼感知到手指的晃动是比远处晃动的“程度”明显的,那么这种程度就是视差在人脑中的反映。
视界
- 深度是通过利用立体匹配系统将视差离散成一系列平行的平面来测量的;每一层平面对应着一个视差。
- 可以通过超像素的方法得到效果更好的深度图。
深度估计
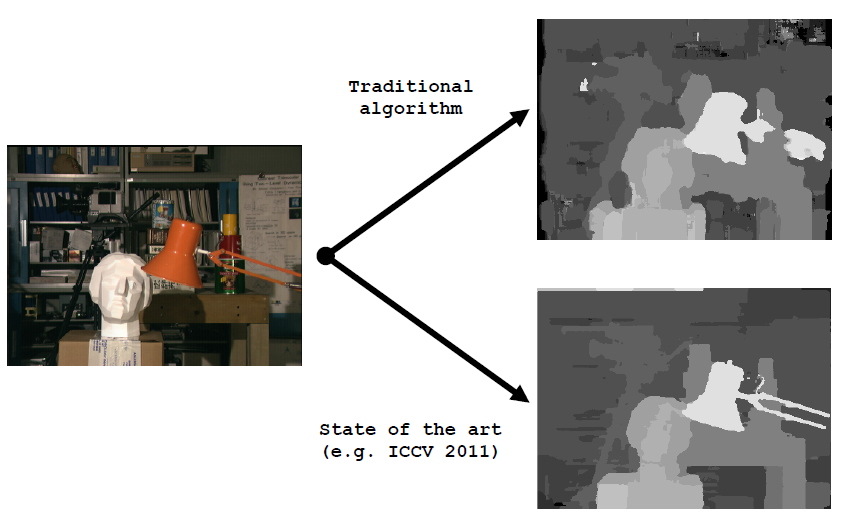 图中为传统算法以及ICCV2011当时最好的结果。可以发现,能够达到较好的视差是具有挑战性的。下面将要展示视差估计的基本流程。
图中为传统算法以及ICCV2011当时最好的结果。可以发现,能够达到较好的视差是具有挑战性的。下面将要展示视差估计的基本流程。
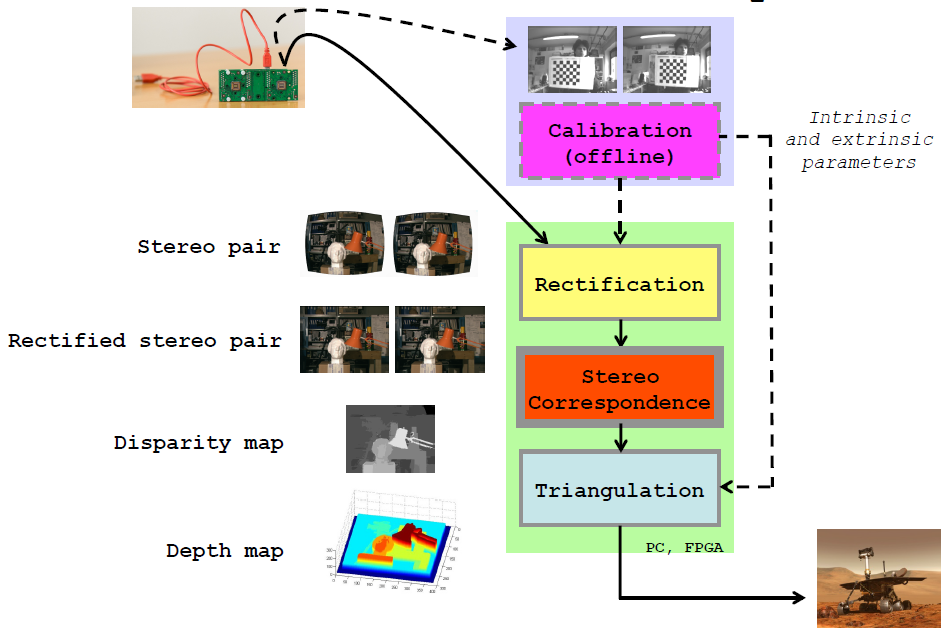 通过双摄设备采集图像,此时图像是存在镜头畸变的,在进行扫描线对齐之前要进行离线标定以消除镜头畸变。扫描线对齐的过程叫做镜头矫正(rectificaition),经过这步之后就可以进行1D的匹配点搜索(stereo correspondence)了。随后通过三角形相似原理得到相应的深度/视差图。
通过双摄设备采集图像,此时图像是存在镜头畸变的,在进行扫描线对齐之前要进行离线标定以消除镜头畸变。扫描线对齐的过程叫做镜头矫正(rectificaition),经过这步之后就可以进行1D的匹配点搜索(stereo correspondence)了。随后通过三角形相似原理得到相应的深度/视差图。
离线标定
 标定的目标是寻找: - 相机内参:焦距、图像中心、镜头畸变参数 - 相机外参:排列相机使其对齐的参数
注意的是,相机标定的话一般需要10对以上的图像(通常拍摄棋盘格图像,利用张氏标定法进行标定)。 - 标定程序可以见Opencv1和Matlab2。 - 更为详细的介绍参见3 4 5。
标定的目标是寻找: - 相机内参:焦距、图像中心、镜头畸变参数 - 相机外参:排列相机使其对齐的参数
注意的是,相机标定的话一般需要10对以上的图像(通常拍摄棋盘格图像,利用张氏标定法进行标定)。 - 标定程序可以见Opencv1和Matlab2。 - 更为详细的介绍参见3 4 5。

 ### 匹配矫正
### 匹配矫正
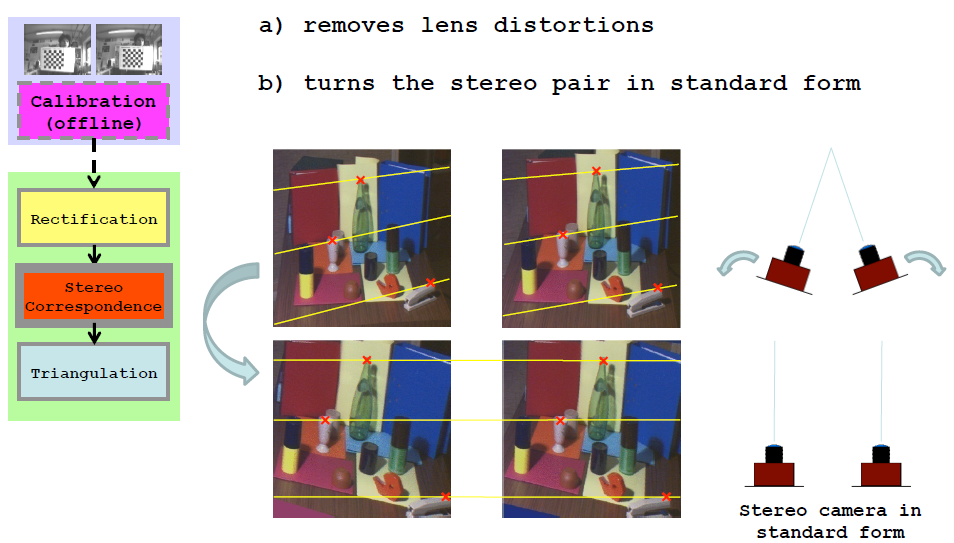 利用标定步骤得到的相机的内参对相机镜头畸变进行校正,同时对其扫描线。
利用标定步骤得到的相机的内参对相机镜头畸变进行校正,同时对其扫描线。
立体匹配
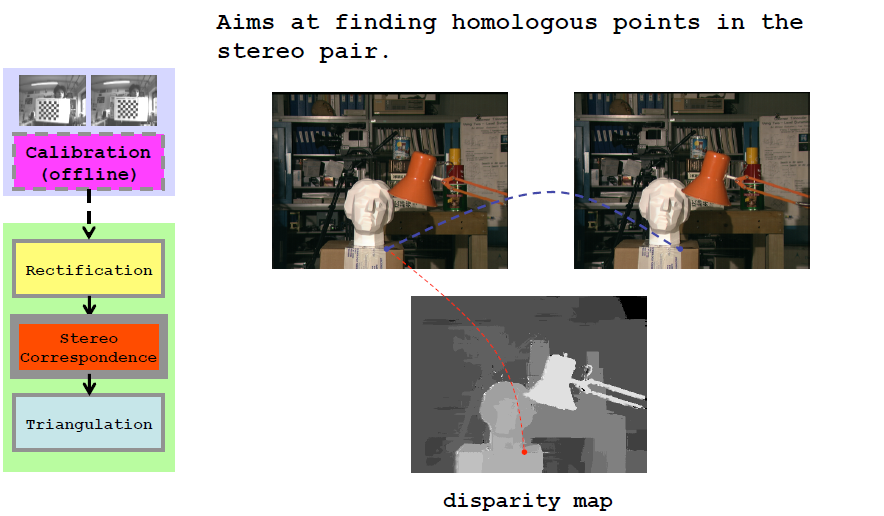 目标:从匹配对中寻找对应的点,反映在图像中就是视差图像。
目标:从匹配对中寻找对应的点,反映在图像中就是视差图像。
三角测量
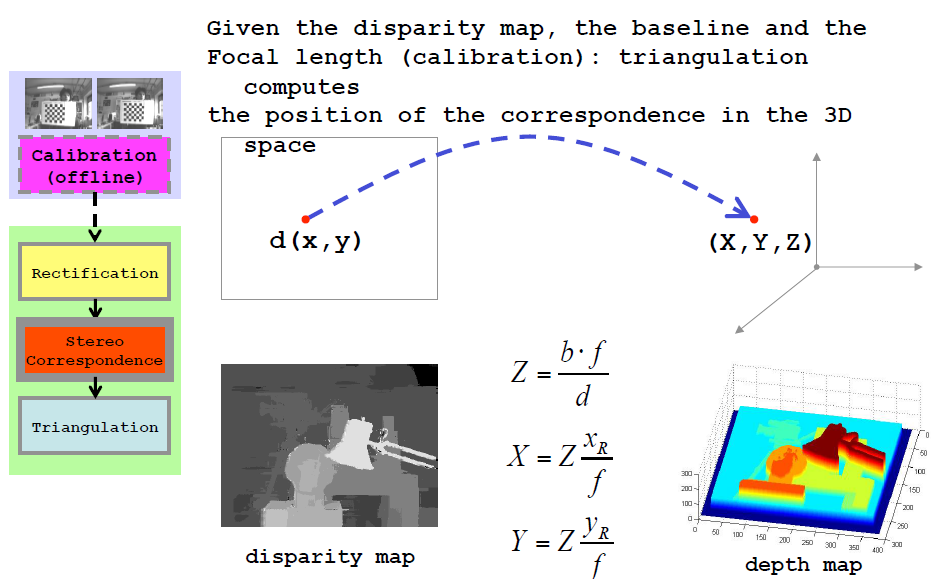 给定视差图像,基线长度以及焦距可以通过三角计算得到当前位置对应的3D位置。
给定视差图像,基线长度以及焦距可以通过三角计算得到当前位置对应的3D位置。
立体匹配的挑战性
光度失真以及噪声
 ### 高光表面
### 高光表面
透视收缩
透视变形
无纹理区域
重复/混淆区域
透明物体
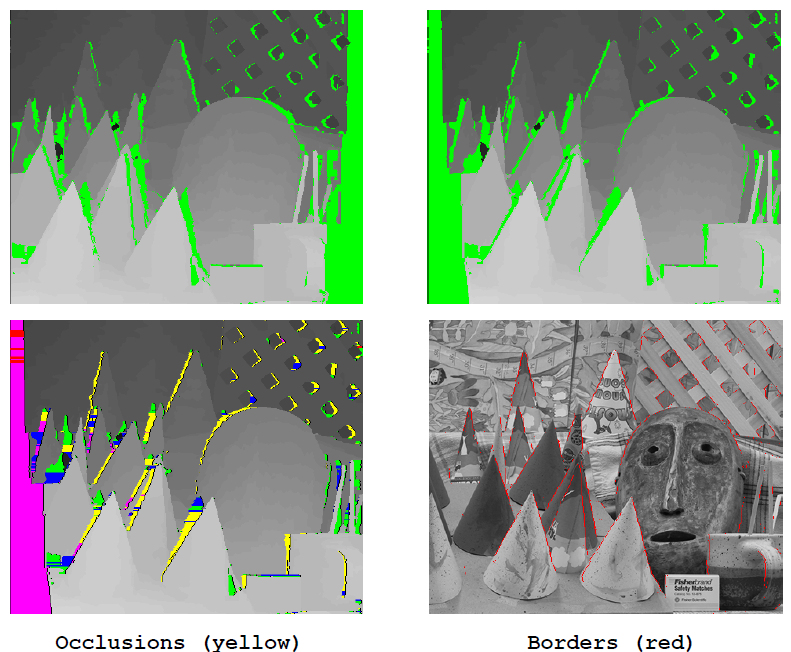
遮挡区以及不连续区域(1)
遮挡区以及不连续区域(2)
Middlebury数据集
Middlebury数据集提供了一套可供深度估计的数据集以及评价系统,深度估计算法可在该数据集上进行测试性能。2003年的数据集提供了Tsukuba, Venus, Teddy and Cones这几个场景的匹配对。
匹配问题
立体匹配的算法可以分成以下几个步骤:
-
匹配量/损失计算
-
损失聚合
-
视差计算/优化
-
视差精化
- 局部算法包括: 1->2->3(简单的WTA算法)
- 全局算法包括: 1(->2)->3(全局或者半全局算法)
数据预处理
数据预处理是为了消除图像的光度失真。常见的操作有: - LoG滤波器6 - 消减附近像素中计算的平均值7 - 双边滤波 - 统计变换
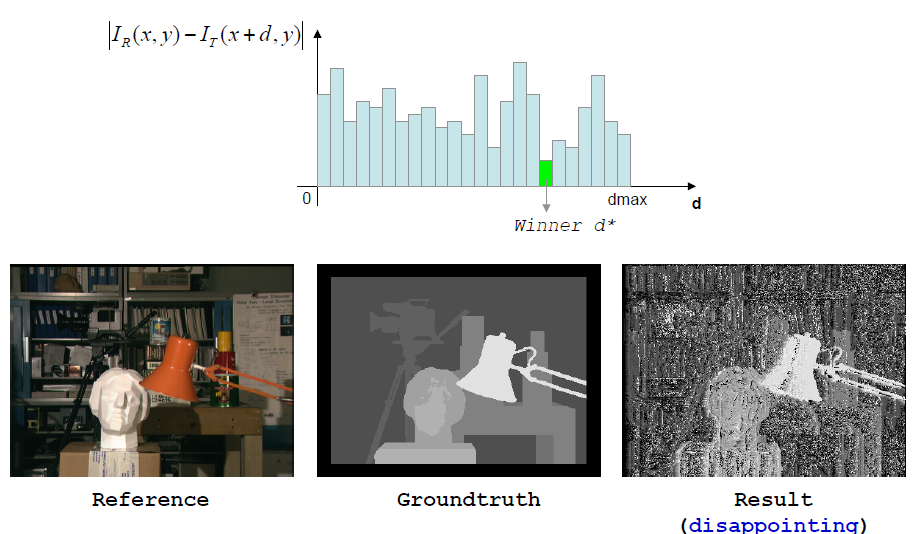
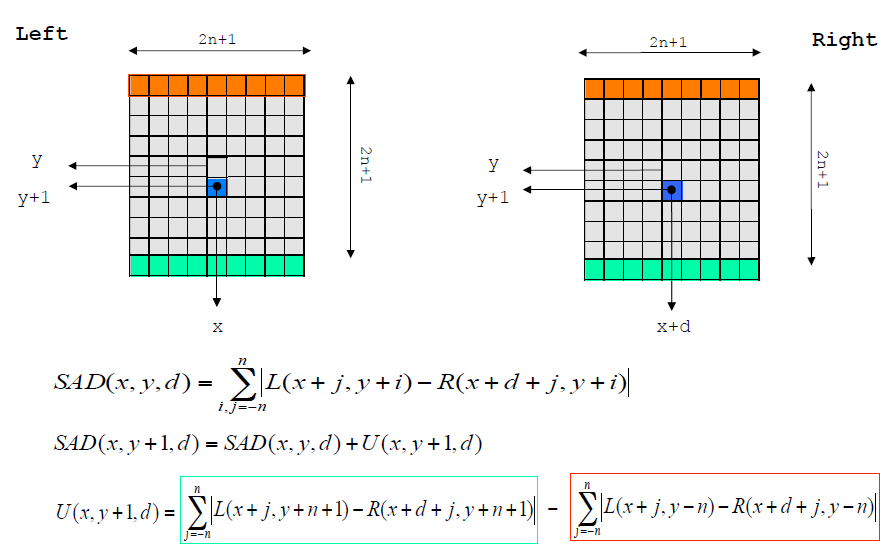
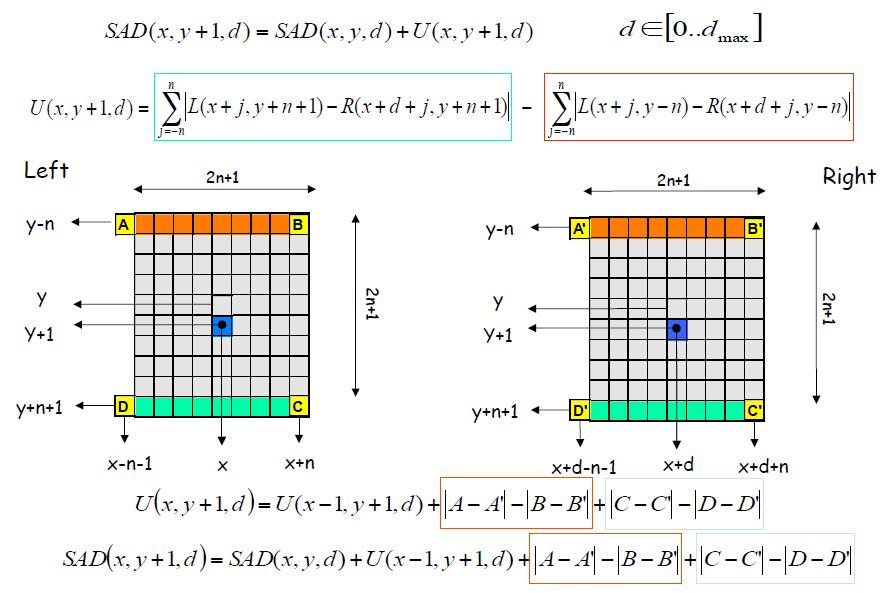
最简单的立体匹配算法如下图所示,逐像素地计算SAD匹配损失;然后通过WTA得到初始视差,但是此时得到的视差质量是很差的。那么如何提高深度图像的质量呢?通常来说有两种不同类别的策略。 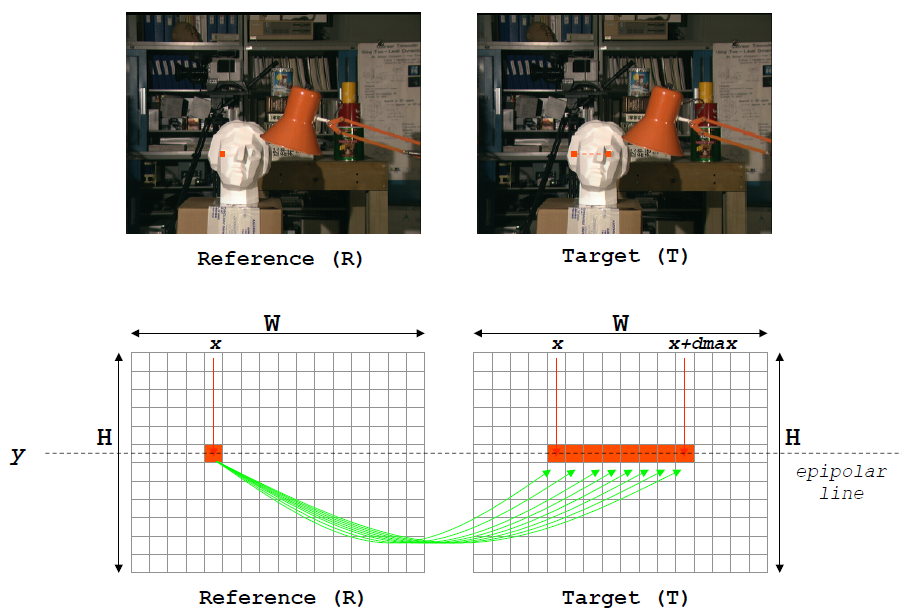
-
局部算法。同样是利用到了简单的WTA提取到初始视差,但是通过计算窗口内的损失量提高了信噪比。有时需会加入平滑项。Steps 1+2 (+ WTA)

-
全局/半全局算法。寻找能够使得能量函数的最小值的视差以得到逐点视差。Steps 1+ Step3。(有时,损失函数需要聚合)









- 鲁棒匹配子(M-estimators) 如截断绝对误差(truncated absolute differences (TAD))可以减少离群点的干扰:
- 相异性测量对于图像噪声不敏感(Birchfield and Tomasi8) ### 区域匹配损失
- 绝对误差和(Sum of Absolute differences (SAD))
其中,就是视差,Z表示深度,B为基线,f是焦距。
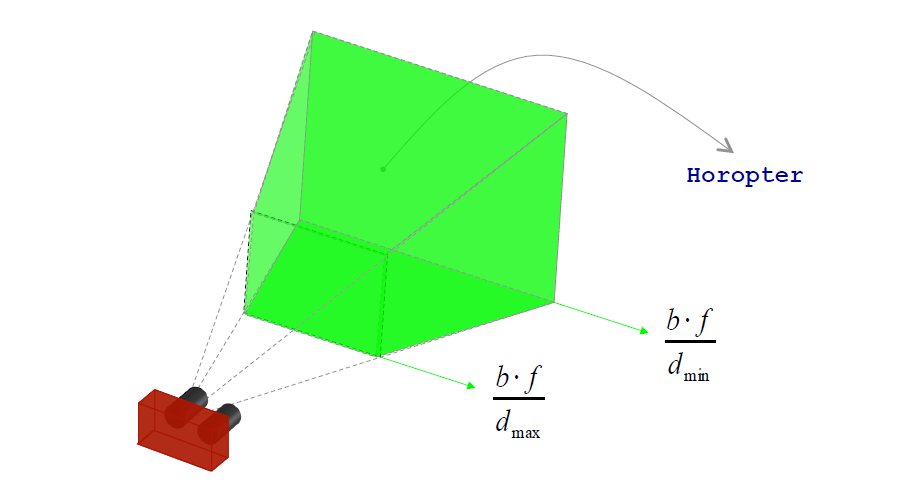
图为双摄装置,基线为b,焦距为f,那么双摄的视界被视差范围所限定{},如图中绿色包裹的区域。
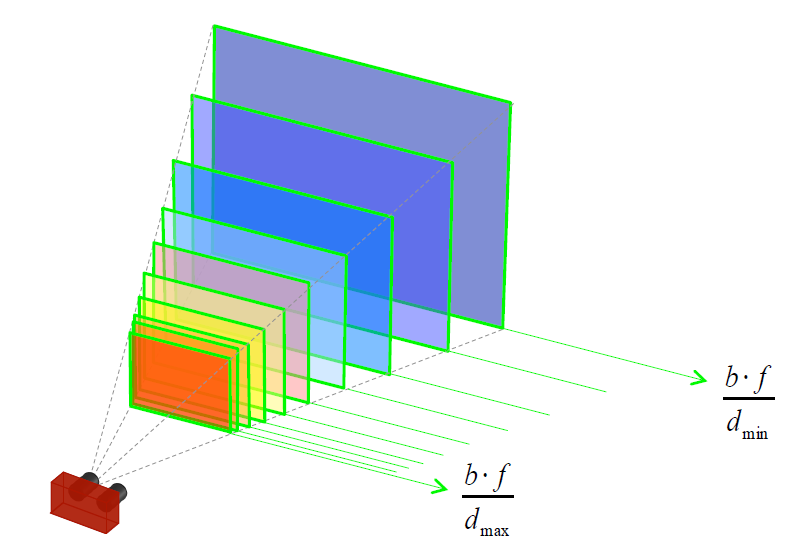
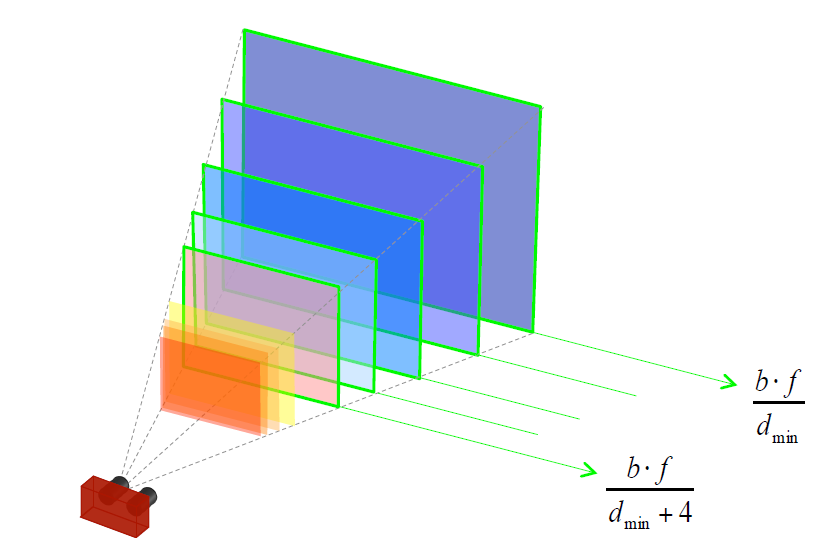 图为5个视差{}组成的视场。
图为5个视差{}组成的视场。
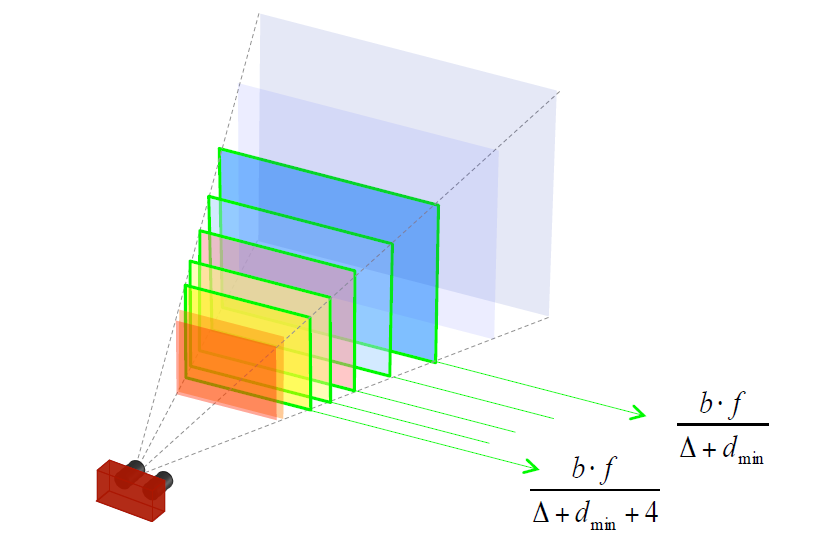 - 图为5个视差{}组成的视场 - 时,视场收缩并向相机靠近
两种算法都假设了匹配对是平滑的,但有时,该假设并不成立。这个假设在局部算法中隐晦地提及,却在全局算法中明确地建模,如下形式。
- 图为5个视差{}组成的视场 - 时,视场收缩并向相机靠近
两种算法都假设了匹配对是平滑的,但有时,该假设并不成立。这个假设在局部算法中隐晦地提及,却在全局算法中明确地建模,如下形式。
损失量的计算
逐像素的匹配误差
- 绝对值误差
- 平方误差
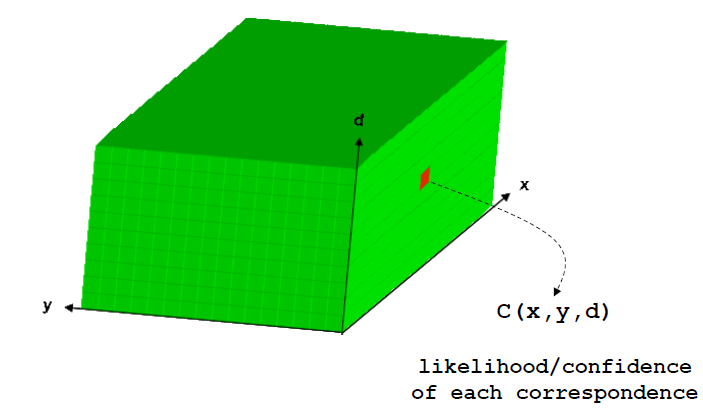
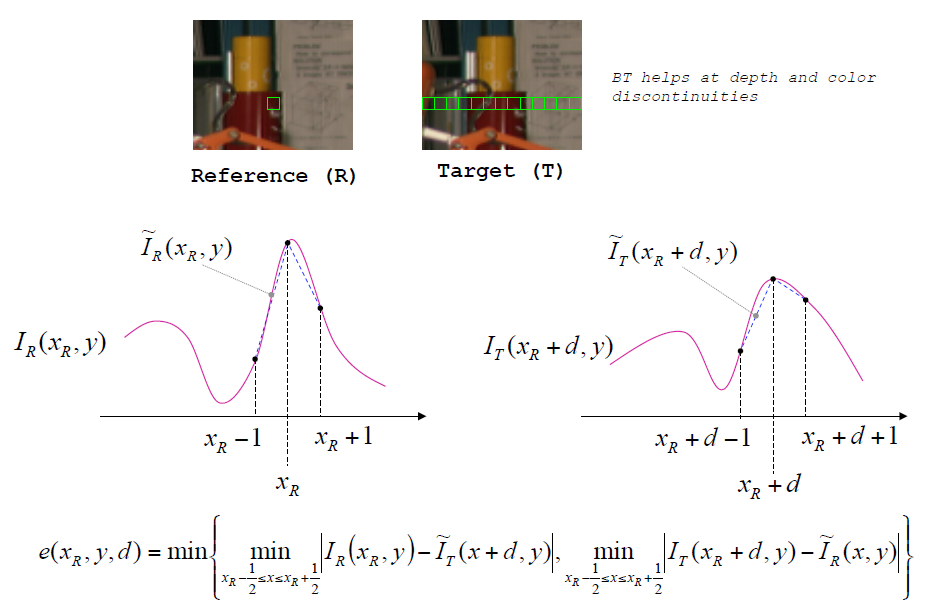 视差空间图像(DSI)是一个如下图所示张量,其中的每一个元素表示与之间的匹配度。 - 绝对平方和(Sum of Squared differences (SSD))
视差空间图像(DSI)是一个如下图所示张量,其中的每一个元素表示与之间的匹配度。 - 绝对平方和(Sum of Squared differences (SSD))
- 截断绝对误差和(Sum of truncated absolute differences (STAD))
- Normalized Cross Correlation 9
- Zero mean Normalized Cross Correlation 10
- Gradient based MF 11
- Non parametric 12 13
- Mutual Information 14
- Combination of matching costs
损失聚合
那么从最简单的固定窗口(FW)损失聚合开始,以下为利用FW聚合的TAD损失然后利用WTA得到的深度图。理想是完美的,但现实是骨感的,可以看到下图给出的结果并不佳,这是什么原因呢? 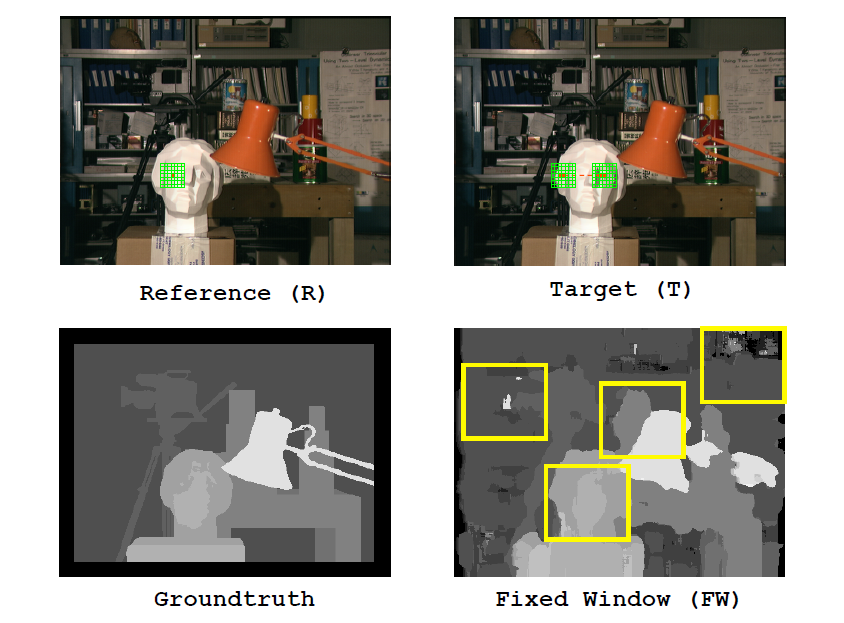
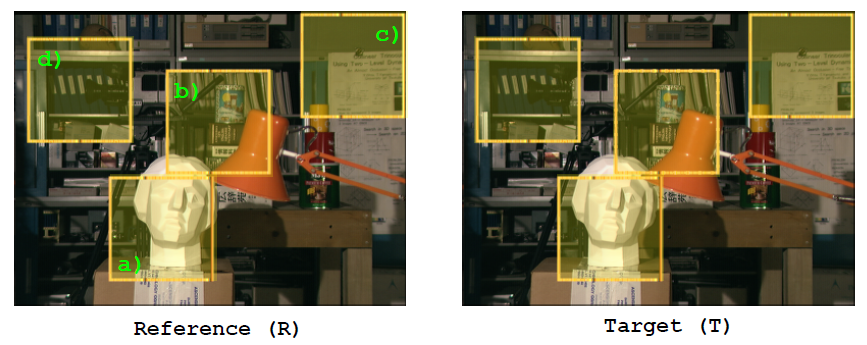 a. 隐含地假设前额表面处于同一视差 b. 忽略了深度的非连续性 c. 平坦区域的处理不佳 d. 重复的区域
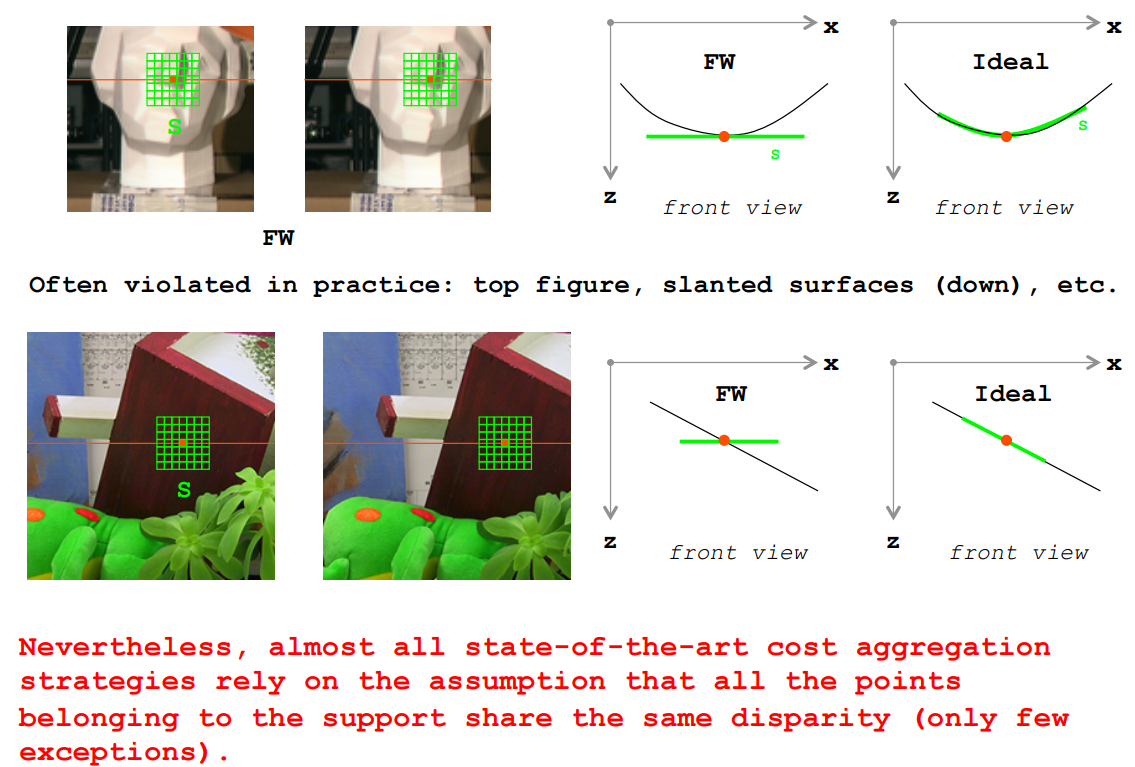
对于a. 隐含地假设前额表面处于同一视差,很多即使是当前最好的损失聚合算法也会假设:在一个小的支持域里面的所有点所处的视差是相同的。但实际情况并非如此,可以观察以上两图,人体头像模型的面部是不规则的表面,展现出来的是视差的不断变化;下面的图是桌子平面,它表面是倾斜的,同样表现出来的是视差的变化。
a. 隐含地假设前额表面处于同一视差 b. 忽略了深度的非连续性 c. 平坦区域的处理不佳 d. 重复的区域
对于a. 隐含地假设前额表面处于同一视差,很多即使是当前最好的损失聚合算法也会假设:在一个小的支持域里面的所有点所处的视差是相同的。但实际情况并非如此,可以观察以上两图,人体头像模型的面部是不规则的表面,展现出来的是视差的不断变化;下面的图是桌子平面,它表面是倾斜的,同样表现出来的是视差的变化。
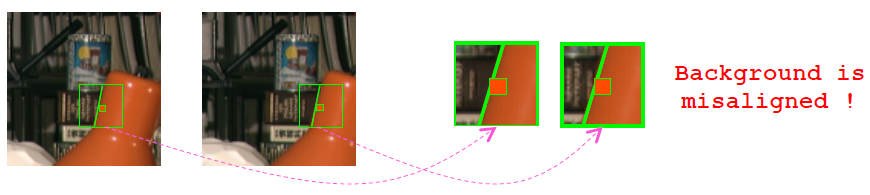
 对于b. 忽略了深度的非连续性,原本假设真实场景中的正面平行表面在支持域内深度不会变化,但是这个假设在深度不连续处的附近被打破。可以看到下图中在台灯灯罩的边界处出现了深度的间断,这样经过损失聚合之后得到的深度就会出现边界误匹配的现象,表现在图中为边界没有很好的对齐。不过利用TAD可以在一定程度上减少这种现象。
对于b. 忽略了深度的非连续性,原本假设真实场景中的正面平行表面在支持域内深度不会变化,但是这个假设在深度不连续处的附近被打破。可以看到下图中在台灯灯罩的边界处出现了深度的间断,这样经过损失聚合之后得到的深度就会出现边界误匹配的现象,表现在图中为边界没有很好的对齐。不过利用TAD可以在一定程度上减少这种现象。
 目前最好的损失聚合算法都在想方设法地改变支持域的形状以适应在仅在相同的已知视差上做匹配。对于FW而言,就是减小其窗口大小,来减少边界定位问题。但是与此同时,这个改变使得匹配问题变得含糊不清,特别是对于有重复区域以及平滑区域的情形。
目前最好的损失聚合算法都在想方设法地改变支持域的形状以适应在仅在相同的已知视差上做匹配。对于FW而言,就是减小其窗口大小,来减少边界定位问题。但是与此同时,这个改变使得匹配问题变得含糊不清,特别是对于有重复区域以及平滑区域的情形。  对于c与d,FW并不能很好地处理。在这两种情况下,损失聚合算法应该不断地加大支持域的尺寸以获得更多的相同深度上的点。
对于c与d,FW并不能很好地处理。在这两种情况下,损失聚合算法应该不断地加大支持域的尺寸以获得更多的相同深度上的点。 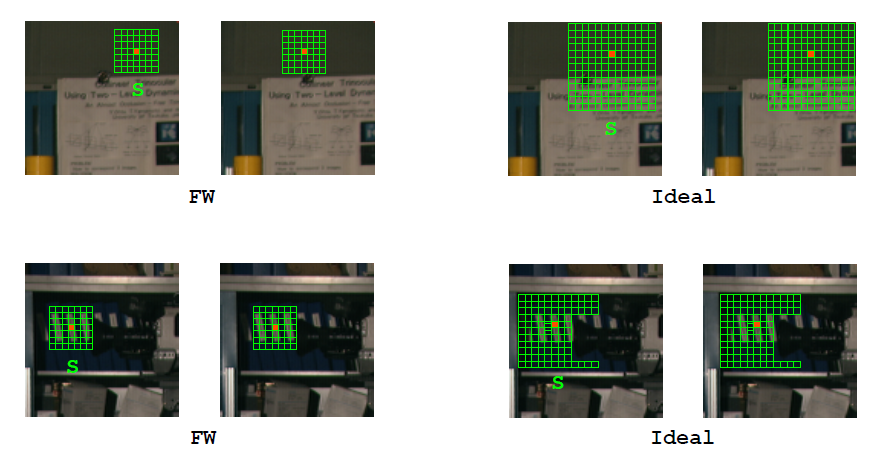 以上为FW所面对的诸多问题。令人吃惊的是,虽然FW看起来如此不堪一击,但是其应用却是如此广泛。原因可能有以下几点: 1. 容易实现; 2. 快!(特别感谢增量计算框架); 3. 可以在传统的处理器上实时完成计算; 4. 仅需要很小的内存; 5. 可硬件(FPGA)实时实现,且功率小(<1W)
在介绍更加复杂的算法之前,我们首先介绍积分图像(Integral Images (II))以及箱滤波(Box-Filtering (BF))。
以上为FW所面对的诸多问题。令人吃惊的是,虽然FW看起来如此不堪一击,但是其应用却是如此广泛。原因可能有以下几点: 1. 容易实现; 2. 快!(特别感谢增量计算框架); 3. 可以在传统的处理器上实时完成计算; 4. 仅需要很小的内存; 5. 可硬件(FPGA)实时实现,且功率小(<1W)
在介绍更加复杂的算法之前,我们首先介绍积分图像(Integral Images (II))以及箱滤波(Box-Filtering (BF))。
积分图像
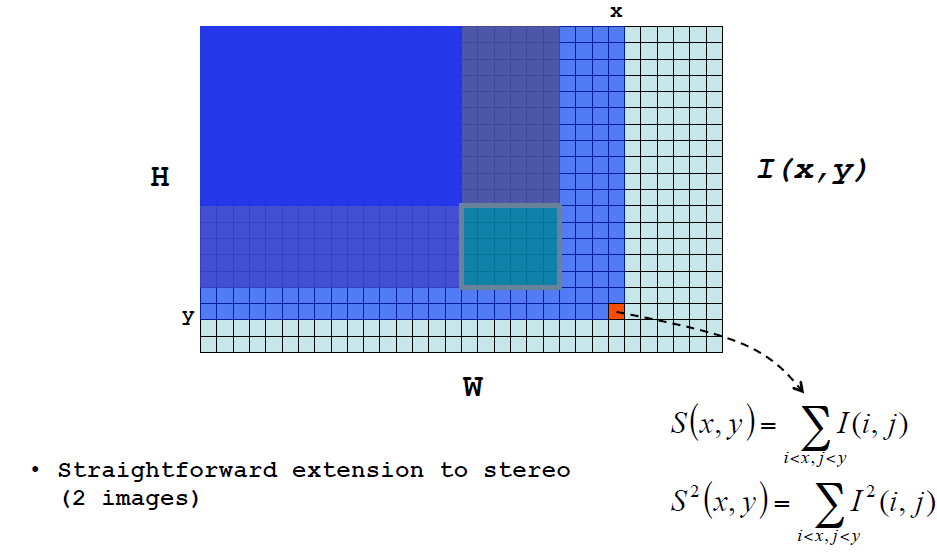
箱滤波器
 可以总结出积分图与箱滤波器的关系: 1. 每个点需要4个运算 2. 积分图可以支持不同的支持域尺寸 3. 积分图有溢出风险 4. 积分图对内存消耗较大
在实际应用当中,积分图对于可变支持域的情况会有帮助。
可以总结出积分图与箱滤波器的关系: 1. 每个点需要4个运算 2. 积分图可以支持不同的支持域尺寸 3. 积分图有溢出风险 4. 积分图对内存消耗较大
在实际应用当中,积分图对于可变支持域的情况会有帮助。
立体匹配中损失聚合策略的分类及评估
在文献15中,作者实现、分类以及评估了超过10种损失聚合算法。这些损失聚合的策略包含几种方式: - 位置 - 方向 - 位置与方向 - 权重 接下来就对文中但不限于文中提到的诸多算法进行介绍 (i.e. Fast Aggregation 16, Fast Bilateral Stereo (FBS) 17 and the Locally Consistent (LC) methodology 18)。
固定窗口

可移动窗口19
这种方法是为了应对场景边界定位问题,这种算法不限制当前位置位于支持域中心。 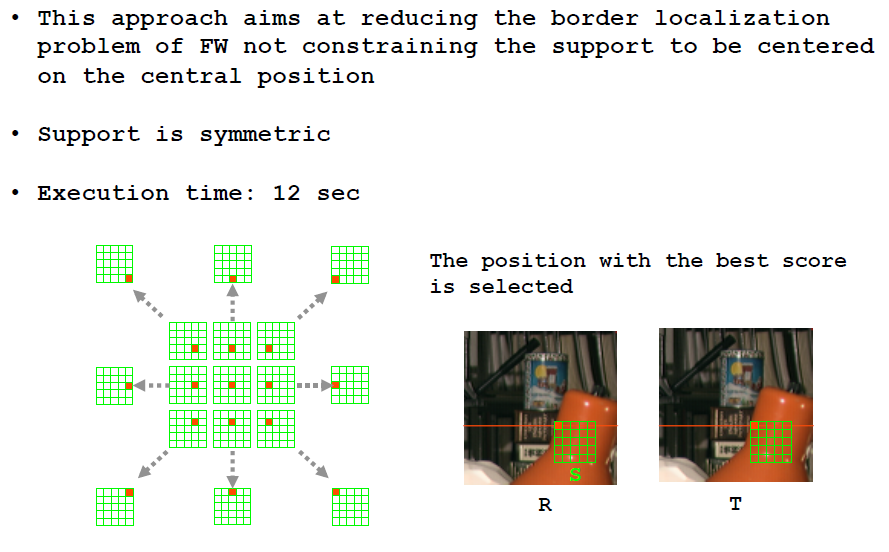

多窗口20
支持域内元素个数为常数;支持域的形状不限于为矩形;支持域大小可为5、9、25(5W,9W,25W)。下图所示的为9W: 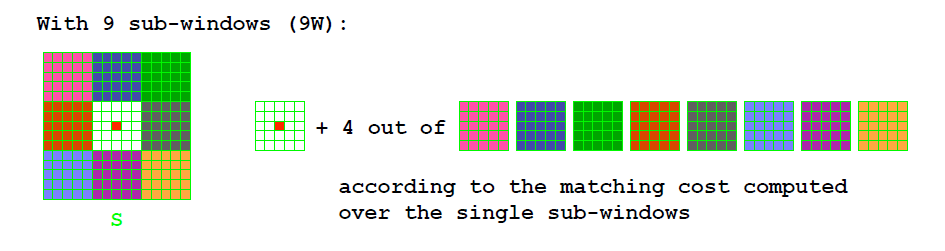


可变窗口21
这种方式,支持域的形状是固定的但是尺寸是变化的。支持域的位置是可变的。 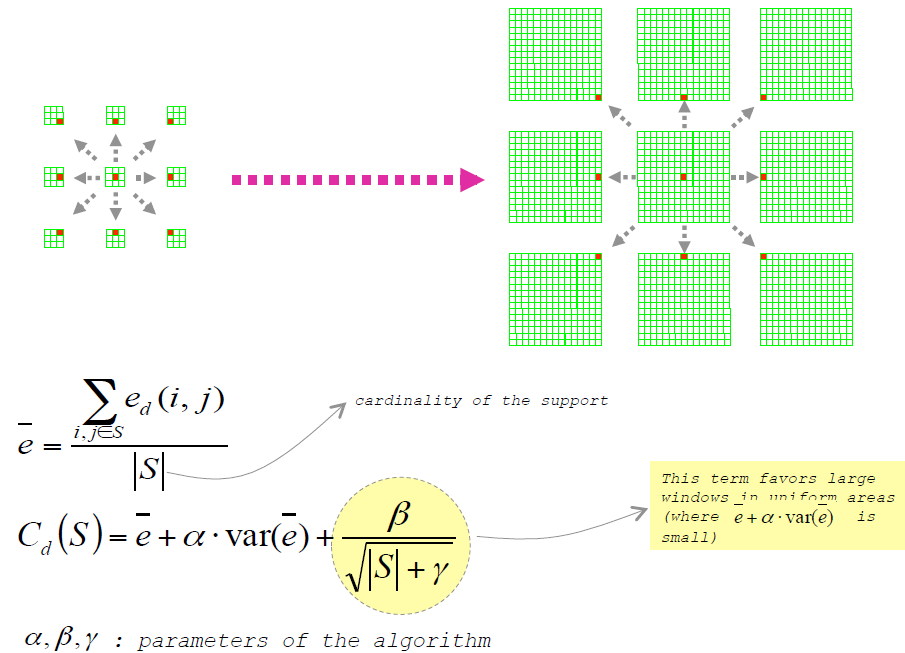

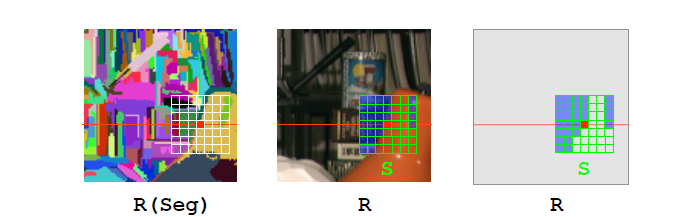
基于分割的窗口22
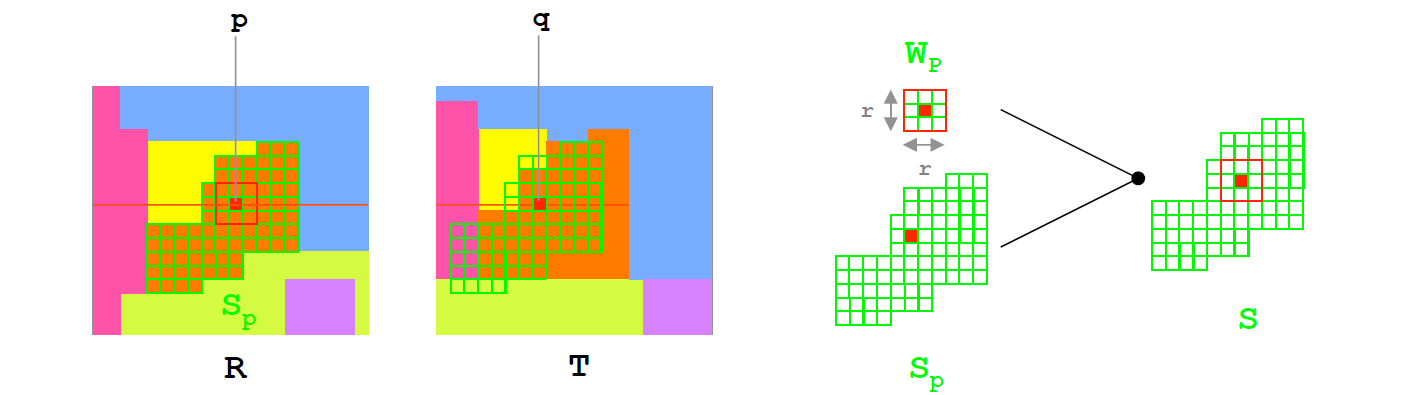
这种方式根据图像的颜色相似性将其分割成一系列图像块,这对于损失聚合、深度图像优化以及离群点检测都有帮助。这种算法假设:每个分割块内深度平滑变化。由于涉及到图像分割此时要求分割的精度很高,并且分割后的每个支持域的形状也是不规则的。如下图所示,对于一个可允许的最大支持域范围内,包含支持域中心点所在的分割所覆盖支持域权重赋值为1,支持域的其余部分赋值为,其中。 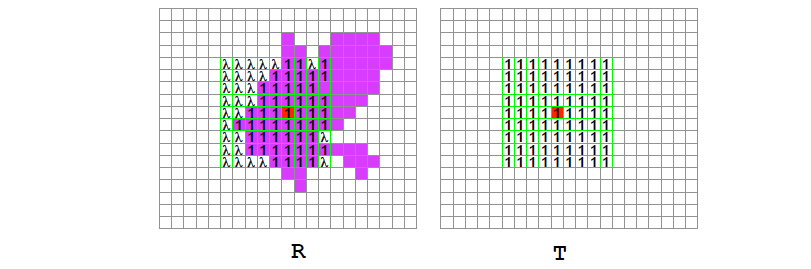

自适应加权23 24
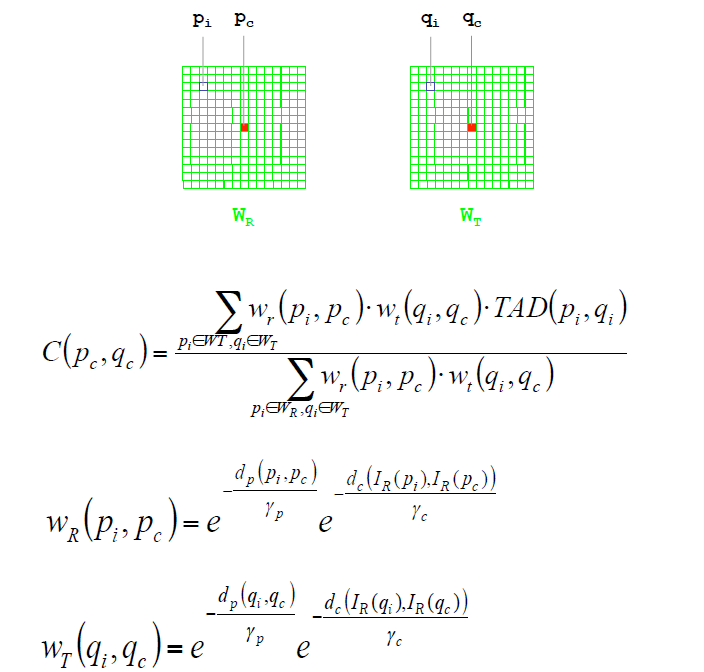
首先介绍双边滤波,双边滤波是一种边缘保持滤波器,它是根据图像的邻域的颜色以及空间相关性对每个中心点进行加权。类似于双边滤波,自适应加权对其进行了简化,只考虑颜色的相关性。每一个损失都被乘以了一个这样的权重可以得到。 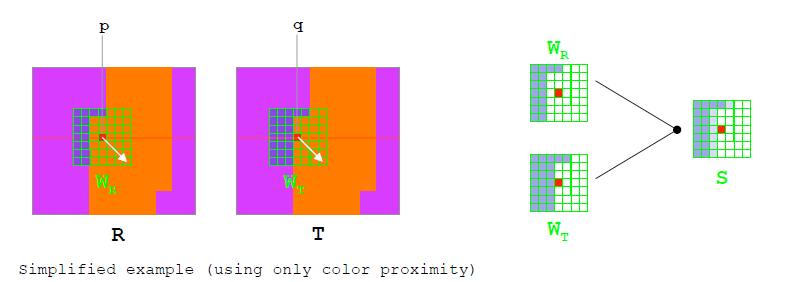
 以下是自适应加权的结果:
以下是自适应加权的结果: 
可分支持域25
快速聚合16
- 假设:在每个分割块内的深度变化平缓;
- 损失量:TAD;
- 只对参考图像进行聚合;
- 对称的支持域
- 支持域覆盖整个分割块
其中为了消除”分割锁定”,这一项可能在纹理稠密的区域很有帮助,但是这一项有可能带来深度的不连续性。 
快速双边滤波17
该方法兼顾了自适应加权的精度以及传统方法的效率。通过逐块的利用双边滤波对损失进行规范化,通过这种方式可以增加对噪声的鲁棒性。可以利用前面提及的积分图或者箱滤波的方式快速计算。由于双边滤波的局部计算特性,可以利用GPU进行加速,GPU加速版本。结果如下所示: 
局部一致性
通过对像素之间的一致性约束进行建模寻找像素之间的相关关系,这种方法对于目前最好的方法具有显著的效果提升。 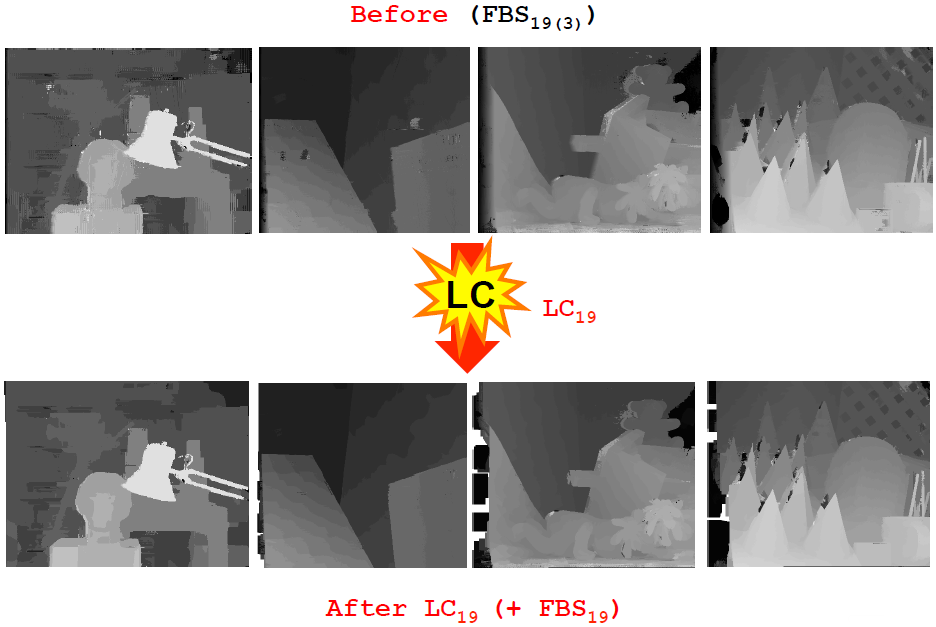
O(1) adaptive cost aggregation26
该方法受引导滤波的启发,效果还不错,可与最佳效果相媲美。 
视差/深度计算以及优化
该步骤是为了寻找可最小化损失函数的视差(或者得到DSI图像的最佳路径以最小化能量函数)。通常情况下,能量函数可以表示为以下形式:
其中的数据项为了衡量目前假定的视差能够以何等程度接近真实视差。目前已经有不少逐像素的损失构造策略,但是目前也涌现了许多基于支持域的数据项。 另外一项是平滑项或者叫做正则项,它可以对像素之间的连续性或者相似性进行约束:这一项对大的视差给予大的惩罚,同时对于边界处的大视差变化以及小的惩罚。也就是说,视差的变化在边界处是被允许的。
以上模型的求解是个NP-hard问题,在这里可以借助几种常用的策略对其进行求解。 - Graph Cuts 27 - Belief Propagation 28 - Cooperative optimization 29
这些方法的比较在[63]中进行了详述。有意思的是,上述问题的解决可以由动态规划以及扫描线优化来解决。
动态规划
- 高效 (polynomial time) ≈ 1 sec
- 边界以及纹理稀疏区域有所帮助
- 条带现象

扫描线优化(Scanline Optimization,SO14)
- 高效 (polynomial time) ≈ few seconds
- 边界以及纹理稀疏区域有所帮助
- 条带现象
- 高内存消耗

视差精化
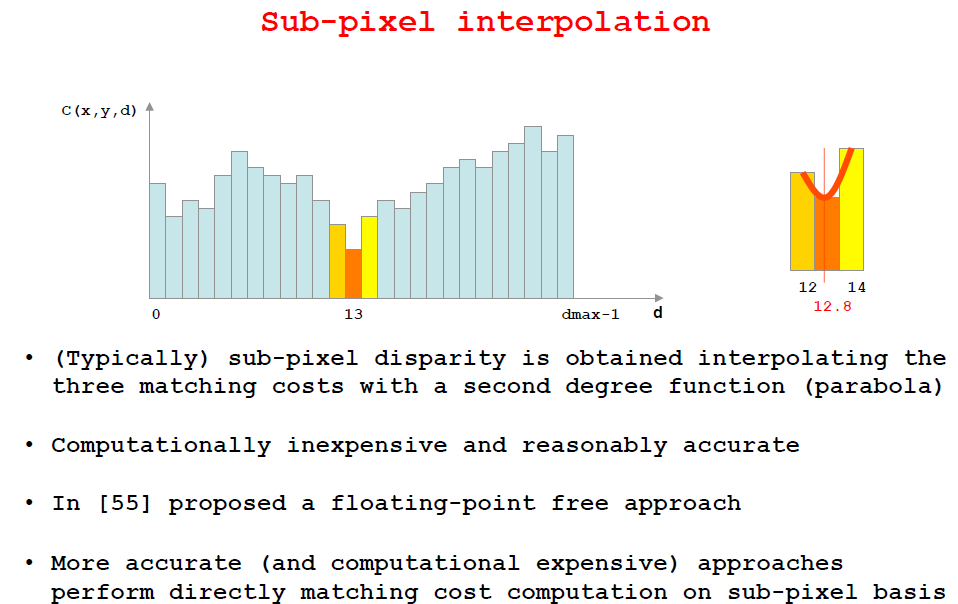
原始视差中包含的离群点需要被检测以及被移除;同时,视差是离散的数据点,有时需要更高的精度;以下将会介绍亚像素插值、图像滤波、双向验证。





未完待续…
**注:**特此感谢Stefano Mattoccia给出如此良心的立体视觉综述,本文最新版本在此(速度较慢)或者这里(较快,大小51.61M)。
Footnotes
-
OpenCV Computer Vision Library, http://sourceforge.net/projects/opencvlibrary/ ↩
-
Jean-Yves Bouguet , Camera Calibration Toolbox for Matlab, http://www.vision.caltech.edu/bouguetj/calib\_doc/ ↩
-
E. Trucco, A. Verri, Introductory Techniques for 3-D Computer Vision, Prentice Hall, 1998 ↩
-
R.I.Hartley, A. Zisserman, Multiple View Geometry in Computer Vision, Cambridge University Press, 2000 ↩
-
G. Bradsky, A. Kaehler, Learning Opencv, O’Reilly, 2008 ↩
-
T. Kanade, H. Kato, S. Kimura, A. Yoshida, and K. Oda, Development of a Video-Rate Stereo Machine International Robotics and Systems Conference (IROS ‘95), Human Robot Interaction and Cooperative Robots, 1995 ↩
-
O. Faugeras, B. Hotz, H. Mathieu, T. Viville, Z. Zhang, P. Fua, E. Thron, L. Moll, G. Berry, Real-time correlation-based stereo: Algorithm. Implementation and Applications, INRIA TR n. 2013, 1993 ↩
-
S. Birchfield and C. Tomasi. A pixel dissimilarity measure that is insensitive to image sampling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(4):401-406, April 1998 ↩
-
S. Mattoccia, F. Tombari, L. Di Stefano, Fast full-search equivalent template matching by Enhanced Bounded Correlation, IEEE Transactions on Image Processing, 17(4), pp 528-538, April 2008 ↩
-
L. Di Stefano, S. Mattoccia, F. Tombari, ZNCC-based template matching using Bounded Partial Correlation Pattern Recognition Letters, 16(14), pp 2129-2134, October 2005 ↩
-
F. Tombari, L. Di Stefano, S. Mattoccia, A. Galanti, Performance evaluation of robust matching measures 3rd International Conference on Computer Vision Theory and Applications (VISAPP 2008) ↩
-
R. Zabih, J John Woodll Non-parametric Local Transforms for Computing Visual Correspondence, ECCV 1994 ↩
-
D. N. Bhat, S. K. Nayar, Ordinal measures for visual correspondence, CVPR 1996 ↩
-
H. Hirschmüller. Stereo vision in structured environments by consistent semi-global matching. CVPR 2006, PAMI 30(2):328-341, 2008 ↩ ↩2
-
F. Tombari, S. Mattoccia, L. Di Stefano, E. Addimanda, Classification and evaluation of cost aggregation methods for stereo correspondence, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR 2008) ↩
-
F. Tombari, S. Mattoccia, L. Di Stefano, E. Addimanda, Near real-time stereo based on effective cost aggregation International Conference on Pattern Recognition (ICPR 2008) ↩ ↩2
-
S. Mattoccia, S. Giardino,A. Gambini, Accurate and efficient cost aggregation strategy for stereo correspondence based on approximated joint bilateral filtering, Asian Conference on Computer Vision (ACCV 2009), September 23-27 2009, Xiang, China ↩ ↩2
-
S. Mattoccia, A locally global approach to stereo correspondence, 3D Digital Imaging and Modeling (3DIM 2009), pp 1763-1770, October 3-4, 2009, Kyoto, Japan ↩
-
D. Scharstein and R. Szeliski, A taxonomy and evaluation of dense two-frame stereo correspondence algorithms Int. Jour. Computer Vision, 47(1/2/3):7–42, 2002. ↩
-
H. Hirschmuller, P. Innocent, and J. Garibaldi, Real-time correlation-based stereo vision with reduced border errors Int. Journ. of Computer Vision, 47:1–3, 2002 ↩
-
O. Veksler. Fast variable window for stereo correspondence using integral images, In Proc. Conf. on Computer Vision and Pattern Recognition (CVPR 2003), pages 556–561, 2003 ↩
-
M. Gerrits and P. Bekaert. Local Stereo Matching with Segmentation-based Outlier Rejection In Proc. Canadian Conf. on Computer and Robot Vision (CRV 2006), pages 66-66, 2006. ↩
-
K. Yoon and I. Kweon, Adaptive support-weight approach for correspondence search, IEEE Trans. PAMI, 28(4):650–656,2006 ↩
-
C. Tomasi and R. Manduchi. Bilateral filtering for gray and color images. In ICCV98, pages 839–846, 1998 ↩
-
F. Tombari, S. Mattoccia, and L. Di Stefano, Segmentation-based adaptive support for accurate stereo correspondence PSIVT 2007 ↩
-
L. De-Maeztu, S. Mattoccia, A. Villanueva, R. Cabeza, “Linear stereo matching”, International Conference on Computer Vision (ICCV 2011), November 6-13, 2011, Barcelona, Spain ↩
-
V. Kolmogorov and R. Zabih, Computing visual correspondence with occlusions using graph cuts, ICCV 2001 ↩
-
A. Klaus, M. Sormann and K. Karner, Segment-based stereo matching using belief propagation and a self-adapting dissimilarity measure, ICPR 2006 ↩
-
Z. Wang and Z. Zheng, A region based stereo matching algorithm using cooperative optimization, CVPR 2008 ↩