📝笔记:SuperPoint: Self-Supervised Interest Point Detection and Description 自监督深度学习特征点
时隔三年,笔者重新研读了这篇论文,仍感觉极富参考价值。笔者更新了这篇于三年前写的文章,主要集中在特征点解码端65通道的解释以及损失函数的理解。
本文出自近几年备受瞩目的创业公司MagicLeap,发表在CVPR 2018,一作Daniel DeTone,[paper],[slides],[code]。
这篇文章设计了一种自监督网络框架,能够同时提取特征点的位置以及描述子。相比于patch-based方法,本文提出的算法能够在原始图像提取到像素级精度的特征点的位置及其描述子。 本文提出了一种单应性适应(Homographic Adaptation)的策略以增强特征点的复检率以及跨域的实用性(这里跨域指的是synthetic-to-real的能力,网络模型在虚拟数据集上训练完成,同样也可以在真实场景下表现优异的能力)。
下面是一作Daniel DeTone关于SuperPoint的讲解(需要科学上网)。
介绍
诸多应用(诸如SLAM/SfM/相机标定/立体匹配)的首要一步就是特征点提取,这里的特征点指的是能够在不同光照&不同视角下都能够稳定且可重复检测的2D图像点位置。
基于CNN的算法几乎在以图像作为输入的所有领域表现出相比于人类特征工程更加优秀的表达能力。目前已经有一些工作做类似的任务,例如人体位姿估计,目标检测以及室内布局估计等。这些算法以通常以大量的人工标注作为GT,这些精心设计的网络用来训练以得到人体上的角点,例如嘴唇的边缘点亦或人体的关节点,但是这里的问题是这里的点实际是ill-defined(我的理解是,这些点有可能是特征点,但仅仅是一个大概的位置,是特征点的子集,并没有真正的把特征点的概念定义清楚)。
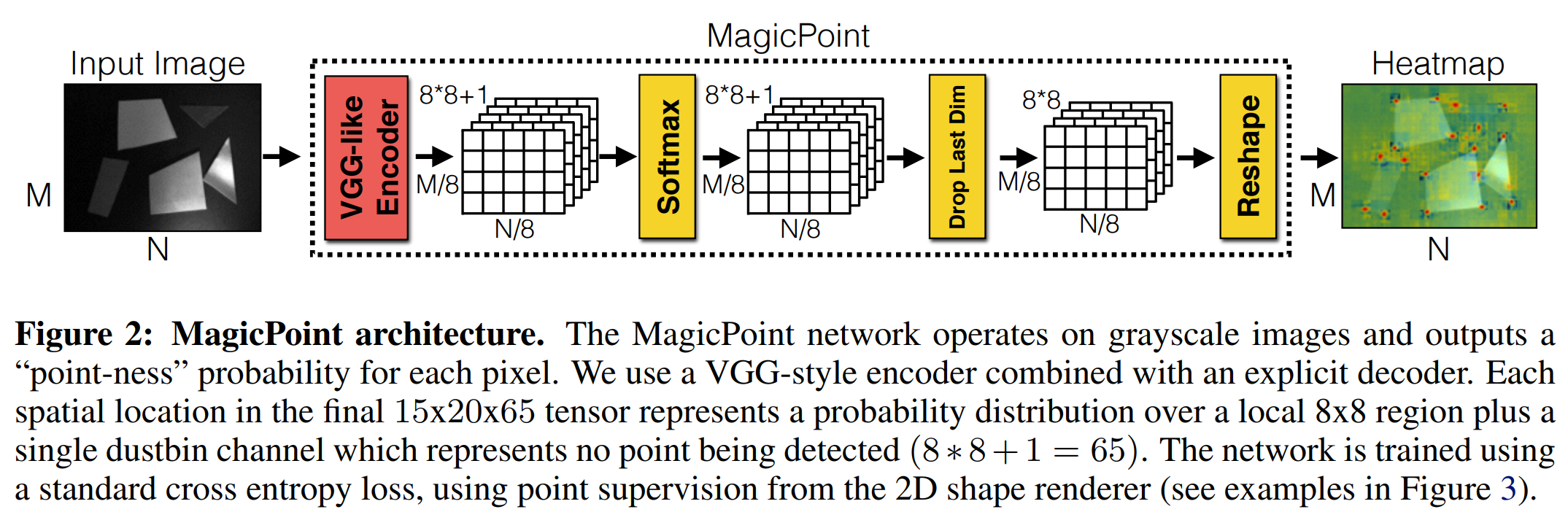
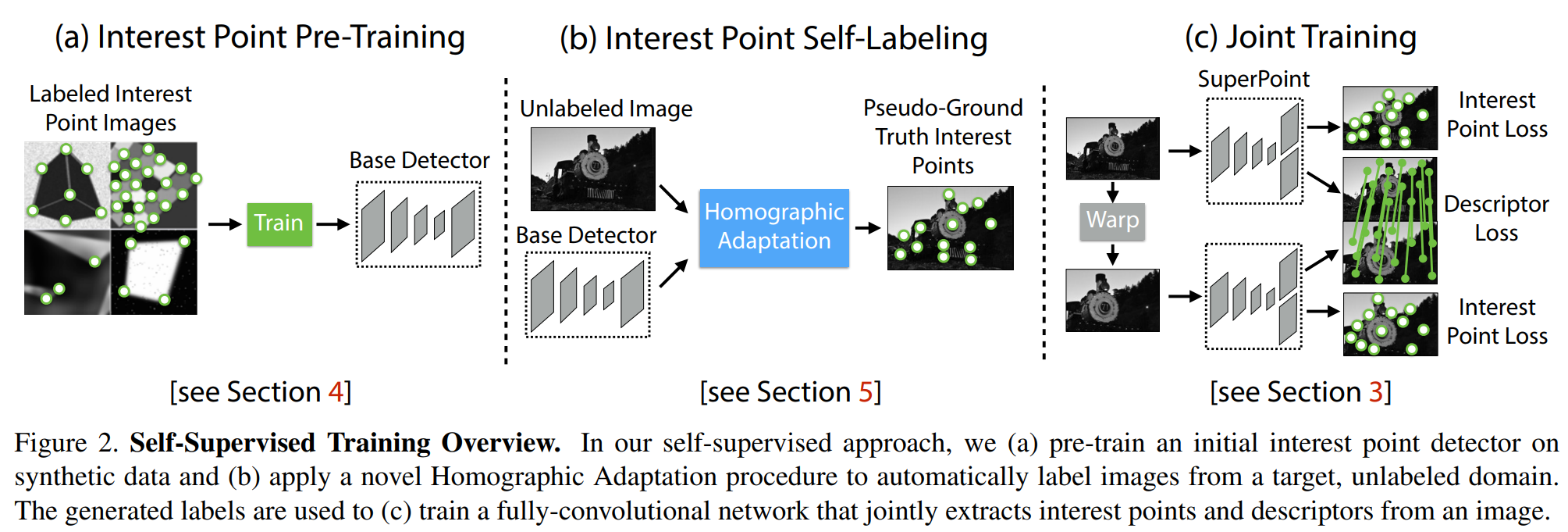
本文采用了非人工监督的方法提取真实场景的特征点。本文设计了一个由特征点检测器监督的具有伪真值数据集,而非是大量的人工标记。为了得到伪真值,本文首先在大量的虚拟数据集上训练了一个全卷积网络(FCNN),这些虚拟数据集由一些基本图形组成,例如有线段、三角形、矩形和立方体等,这些基本图形具有没有争议的特征点位置,文中称这些特征点为MagicPoint,这个pre-trained的检测器就是MagicPoint检测器。这些MagicPoint在虚拟场景的中检测特征点的性能明显优于传统方式,但是在真实的复杂场景中表现不佳,此时作者提出了一种多尺度多变换的方法Homographic Adaptation。对于输入图像而言,Homographic Adaptation通过对图像进行多次不同的尺度/角度变换来帮助网络能够在不同视角不同尺度观测到特征点。 综上:SuperPoint = MagicPoint+Homographic Adaptation
算法优劣对比
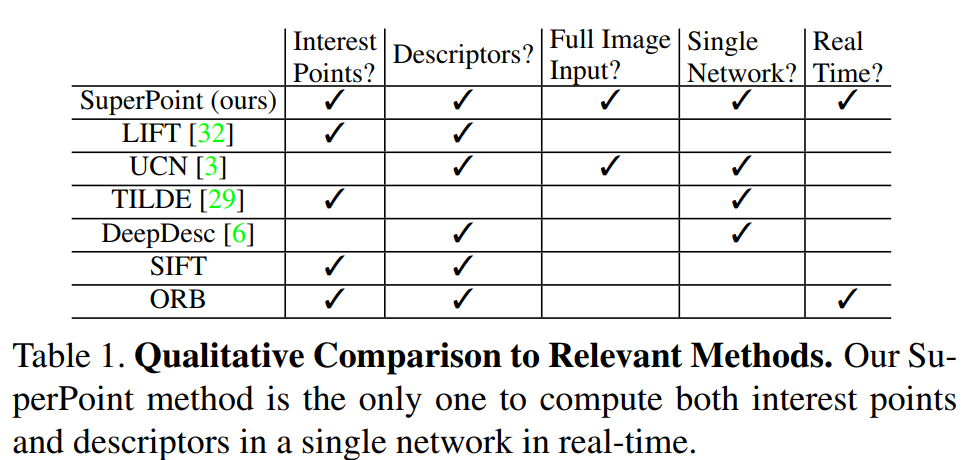
- 基于图像块的算法导致特征点位置精度不够准确;
- 特征点与描述子分开进行训练导致运算资源的浪费,网络不够精简,实时性不足;或者仅仅训练特征点或者描述子的一种,不能用同一个网络进行联合训练;
网络结构
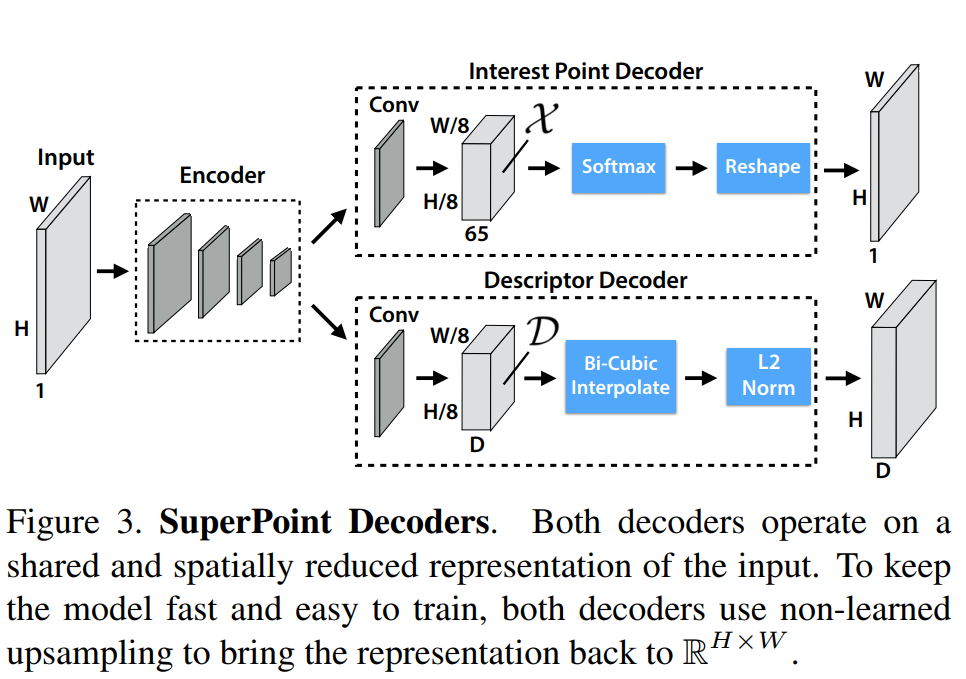
上图可见特征点检测器以及描述子网络共享一个单一的前向encoder,只是在decoder时采用了不同的结构,根据任务的不同学习不同的网络参数。这也是本框架与其他网络的不同之处:其他网络采用的是先训练好特征点检测网络,然后再去进行对特征点描述网络进行训练。 网络共分成以下4个主要部分,在此进行详述。
1. Shared Encoder 共享的编码网络
之后,图像由:
变成和,经过encoder之后,图像由变为张量。
2. Interest Point Decoder
这里介绍的是特征点的解码端。每个像素的经过该解码器的输出是该像素是特征点的概率(probability of “point-ness”)。 通常而言,我们可以通过反卷积得到上采样的图像,但是这种操作会导致计算量的骤增以及会引入一种“checkerboard artifacts”。因此本文设计了一种带有“特定解码器”(这种解码器没有参数)的特征点检测头以减小模型计算量(子像素卷积)。 例如:输入张量的维度是,输出维度,即图像的尺寸。这里的65表示原图的局部区域,加上一个非特征点dustbin。通过在channel维度上做softmax,非特征点dustbin会被删除,同时会做一步图像的reshape:。(这就是**子像素卷积**的意思,俗称像素洗牌)
抛出特征点解码端部分代码:
# Compute the dense keypoint scores
cPa = self.relu(self.convPa(x))
scores = self.convPb(cPa) # DIM: N x 65 x H/8 x W/8
scores = torch.nn.functional.softmax(scores, 1)[:, :-1] # DIM: N x 64 x H/8 x W/8
b, _, h, w = scores.shape
scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8) # DIM: N x H/8 x W/8 x 8 x 8
scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8) # DIM: N x H x W这个过程看似比较繁琐,但是这其实就是一个由depth to space的过程,以N = 1为例,上述过程如下图所示:
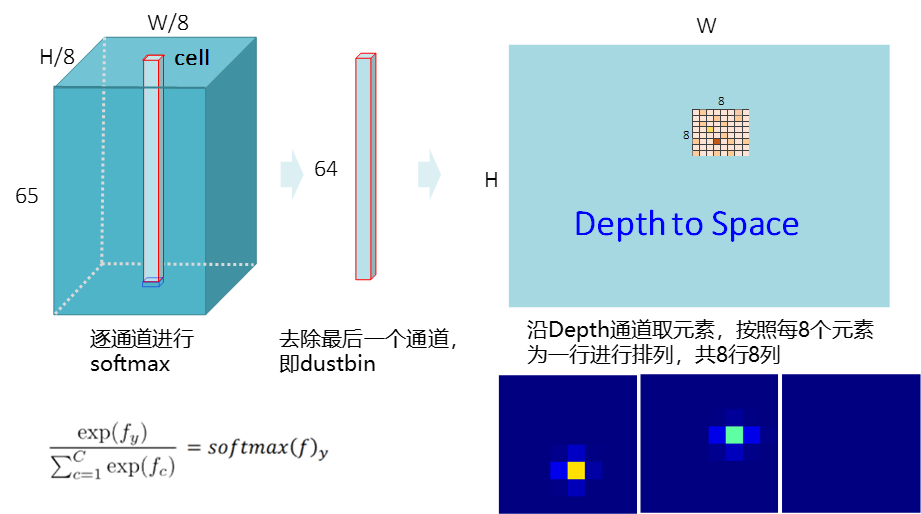
上图中所示的3个蓝色小块的就是对应的一个cell经过depth to space后得到的,易知其尺寸是。
注意 :这里解释一下为何此作者设置选择增加一个dustbin通道,以及为何先进行softmax再进行slice操作,先进行slice再进行softmax是否可行?(
scores = torch.nn.functional.softmax(scores, 1)[:, :-1])
之所以要设置65个通道,这是因为算法要应对不存在特征点的情况。注意到之后的一步中使用了softmax,也就是说沿着通道维度把各个数值通过运算后加和为1。如果没有Dustbin通道,这里就会产生一个问题:若该cell处没有特征点,此时经过softmax后,每个通道上的响应就会出现受到噪声干扰造成异常随机,在随后的特征点选择一步中会将非特征点判定为特征,这个过程由下图左图所示。在添加Dustbin之后,在没有特征的情况下,只有在Dustbin通道的响应值很大,在后续的特征点判断阶段,此时该图像块的响应都很小,会成功判定为无特征点,这个过程由下图右图所示。
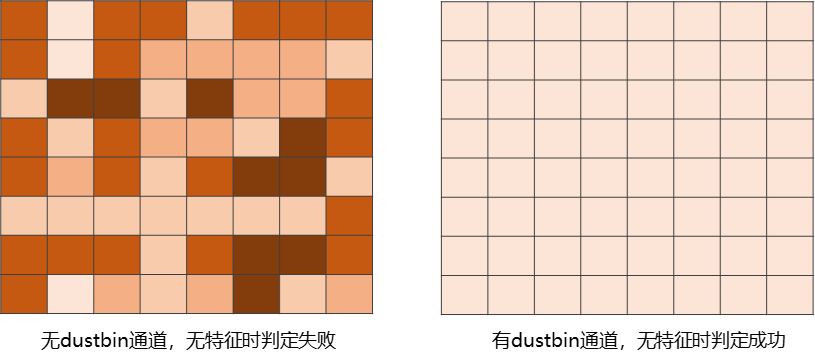
上述过程中得到的scores就是图像上特征点的概率(或者叫做特征响应,后文中响应值即表示概率值),概率越大,该点越有可能是特征点。之后作者进行了一步nms,即非极大值抑制(simple_nms的实现见文末),随后选择响应值较大的位置作为特征点。
scores = simple_nms(scores, self.config['nms_radius'])
keypoints = [ torch.nonzero(s > self.config['keypoint_threshold']) for s in scores]nms的效果如下,左图是未使用nms时score的样子,响应值极大的位置周围也聚集着响应较大的点,如果不进行nms,特征点将会很集中;右图是进行nms操作后的score,响应值极大的位置周围的响应为0。

nms前后对应的特征点的位置如下所示,可见nms对于避免特征点位置过于集中起到了比较大的作用。

熟悉SuperPoint的同学应该注意到了,Daniel在CVPR 2018公开的实现中nms在特征点提取之后,而Sarlin于CVPR 2020年公开SuperGlue的同时对SuperPoint进行了重构,后者在score上进行nms,这两种实现上存在一些差异。
下面给出的是Daniel在CVPR 2018开源的SuperPoint推理代码节选。
nodust = nodust.transpose(1, 2, 0)
heatmap = np.reshape(nodust, [Hc, Wc, self.cell, self.cell])
heatmap = np.transpose(heatmap, [0, 2, 1, 3])
heatmap = np.reshape(heatmap, [Hc*self.cell, Wc*self.cell])
xs, ys = np.where(heatmap >= self.conf_thresh) # Confidence threshold.
if len(xs) == 0:
return np.zeros((3, 0)), None, None
pts = np.zeros((3, len(xs))) # Populate point data sized 3xN.
pts[0, :] = ys
pts[1, :] = xs
pts[2, :] = heatmap[xs, ys]
pts, _ = self.nms_fast(pts, H, W, dist_thresh=self.nms_dist) # Apply NMS.但Sarlin为何要这么做呢?本人在Github上提交了一个#issue112咨询了Sarlin,如下是他的回复,总结起来就重构后的代码优势有两点:1. 更加快速,能够在GPU上运行,常数级时间复杂度;2. 支持多图像输入。
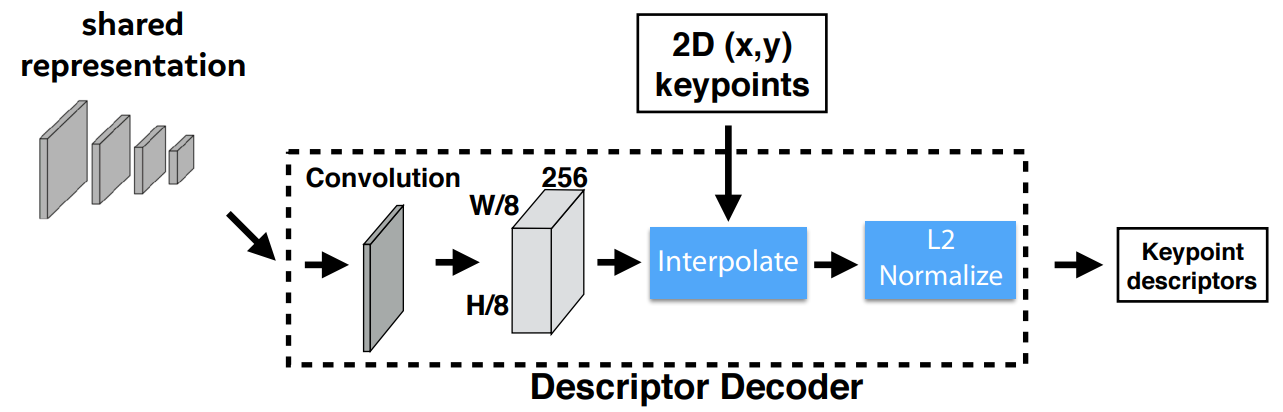
3. Descriptor Decoder
归一化描述子得到统一的长度描述。特征维度由:
变为 。
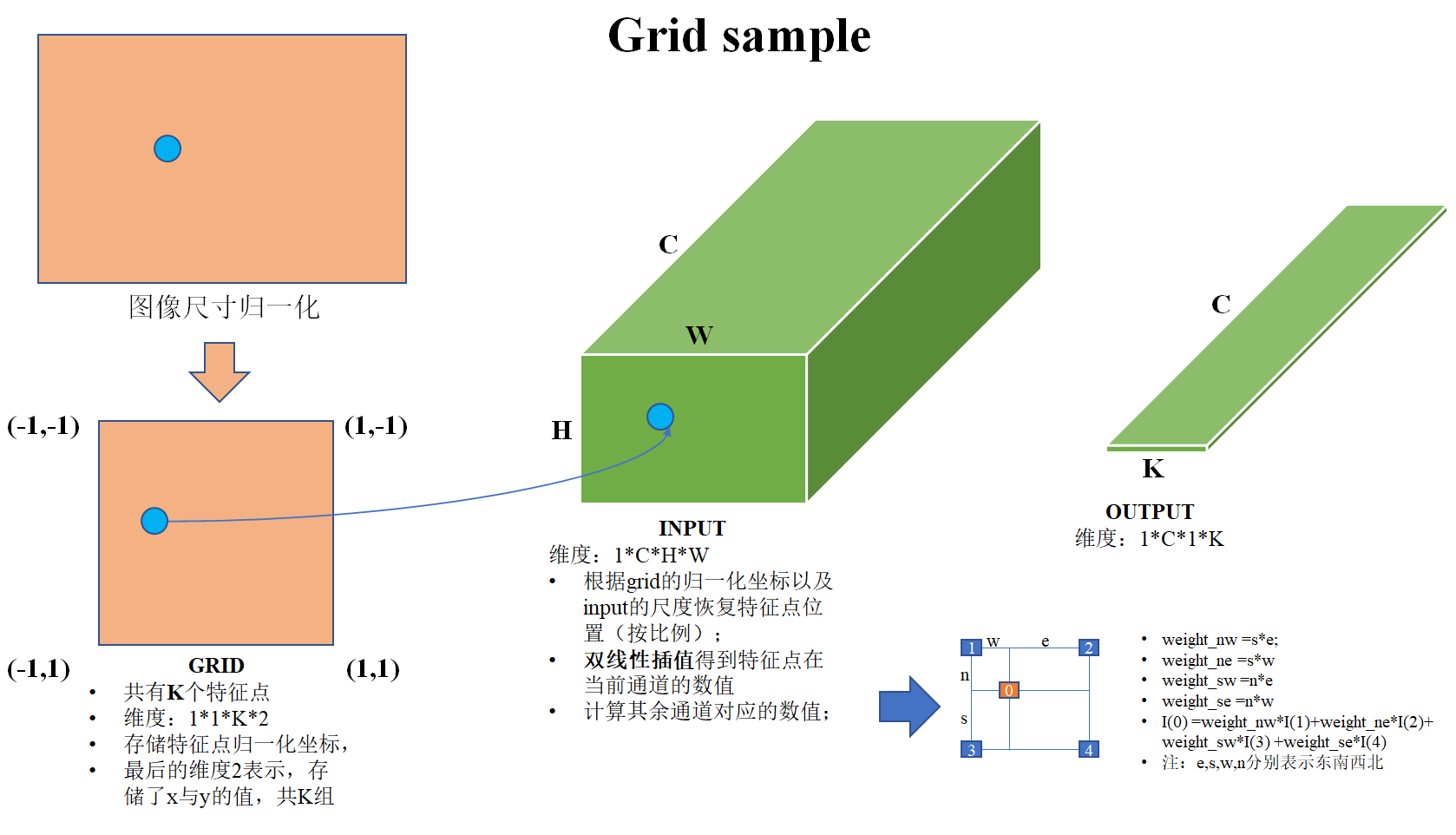
由特征点得到其描述子的过程文中没有细讲,看了一下源代码就明白了。其实该过程主要用了一个函数即grid_sample,画了一个草图作为解释。
- 图像尺寸归一化:首先对图像的尺寸进行归一化,(-1,-1)表示原来图像的(0,0)位置,(1,1)表示原来图像的(H-1,W-1)位置,这样一来,特征点的位置也被归一化到了相应的位置。
- 构建grid:将归一化后的特征点罗列起来,构成一个尺度为1*1*K*2的张量,其中K表示特征数量,2分别表示xy坐标。
- 特征点位置反归一化:根据输入张量的H与W对grid(1,1,0,:)(表示第一个特征点,其余特征点类似)进行反归一化,其实就是按照比例进行缩放+平移,得到反归一化特征点在张量某个slice(通道)上的位置;但是这个位置可能并非为整像素,此时要对其进行双线性插值补齐,然后其余slice按照同样的方式进行双线性插值。注:代码中实际的就是双线性插值,并非文中讲的双三次插值;
- 输出维度:1*C*1*K。
描述子解码部分代码如下:
# Compute the dense descriptors
cDa = self.relu(self.convDa(x))
descriptors = self.convDb(cDa) # DIM: N x 256 x H/8 x W/8
descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1) #按通道进行归一化
# Extract descriptors
# 根据特征点位置插值得到描述子, DIM: N x 256 x M
descriptors = [sample_descriptors(k[None], d[None], 8)[0]
for k, d in zip(keypoints, descriptors)]4. 误差构建
可见损失函数由两项组成,其中一项为特征点检测loss ,另外一项是描述子的loss。
对于检测项loss,此时采用了交叉熵损失函数:
其中:
此时类似于一个多分类任务, 运算内部就是cell中元素为特征点的概率(即softmax之后的值),即样本属于特征的概率。这是一个2D location classifier,每个8x8的范围内只能有一个特征点,即图像中最多有个SuperPoint特征点。
描述子的损失函数:
其中为Hinge-loss(合页损失函数,用于SVM,如支持向量的软间隔,可以保证最后解的稀疏性):
同时指示函数为,表示所有正确匹配对集合:
网络训练
本文一共设计了两个网络,一个是BaseDetector,用于检测角点(注意,此处提取的并不是最终输出的特征点,可以理解为候选的特征点),另一个是SuperPoint网络,输出特征点和描述子。
网络的训练共分为三个步骤: 1. 第一步是采用虚拟的三维物体作为数据集,训练网络去提取角点,这里得到的是BaseDetector即,MagicPoint; 2. 使用真实场景图片,用第一步训练出来的网络MagicPoint +Homographic Adaptation提取角点(这一步迭代使用1-2次效果就可以非常棒),这一步称作兴趣点自标注(Interest Point Self-Labeling) 3. 对第二步使用的图片进行几何变换(即单应变换)得到新的图片,这样就有了已知位姿关系的图片对,把这两张图片输入SuperPoint网络,提取特征点和描述子。
这里需要注意的是,联合训练使用的单应变换相较于Homographic Adaptation中设置的单应变换更加严格,即没有特别离谱的in-plane的旋转。作者在论文中提到,这是由于在HPatches数据集中没有这样的数据才进行这种设置,原话是“we avoid sampling extreme in-plane rotations as they are rarely seen in HPatches”,这也是为什么SuperPoint无法有效地应对in-plane rotations的原因。
## 预训练Magic Point
上式中的是cell的中心点坐标,与的距离小于8个pixel的认为是正确的匹配,这其实对应于cell上的的1个pixel。
让我们仔细看一下这个损失函数,这其实是一个Double margin Siamese loss。当正例描述子余弦相似度大于时,此时不需要惩罚;但如果该相似度较小时,此时就要惩罚了;负样本时我们的目标是让变小,但网络性能不佳时可能这个值很大(大于上式中的),此时要惩罚这种现象,网络权重经过调整后使得该loss降低,对应的描述子相似度降低;
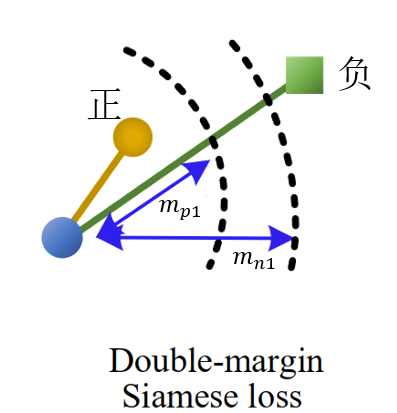
让我们再看一下这个所谓的Double margin Siamese loss,上图示中的连线表示函数。想象一下,我们希望正例越小越好,如果,网络要惩罚这种现象,会使得.相应的的我们希望负例越大越好,如果,网络要惩罚这种现象,最终会使得。
此处参考作者之前发表的一篇论文**[Toward Geometric Deep SLAM]**,其实就是MagicPoint,它仅仅保留了SuperPoint的主干网络以及特征点解码端,即SuperPoint的检测端就是MagicPoint。

## Homographic Adaptation
算法在虚拟数据集上表现极其优秀,但是在真实场景下表示没有达到预期,此时本文进行了Homographic Adaptation。 作者使用的数据集是MS-COCO,为了使网络的泛化能力更强,本文不仅使用原始了原始图片,而且对每张图片进行随机的旋转和缩放形成新的图片,新的图片也被用来进行识别。这一步其实就类似于训练里常用的数据增强。经过一系列的单应变换之后特征点的复检率以及普适性得以增强。值得注意的是,在实际训练时,这里采用了迭代使用单应变换的方式,例如使用优化后的特征点检测器重新进行单应变换进行训练,然后又可以得到更新后的检测器,如此迭代优化,这就是所谓的self-supervisd。 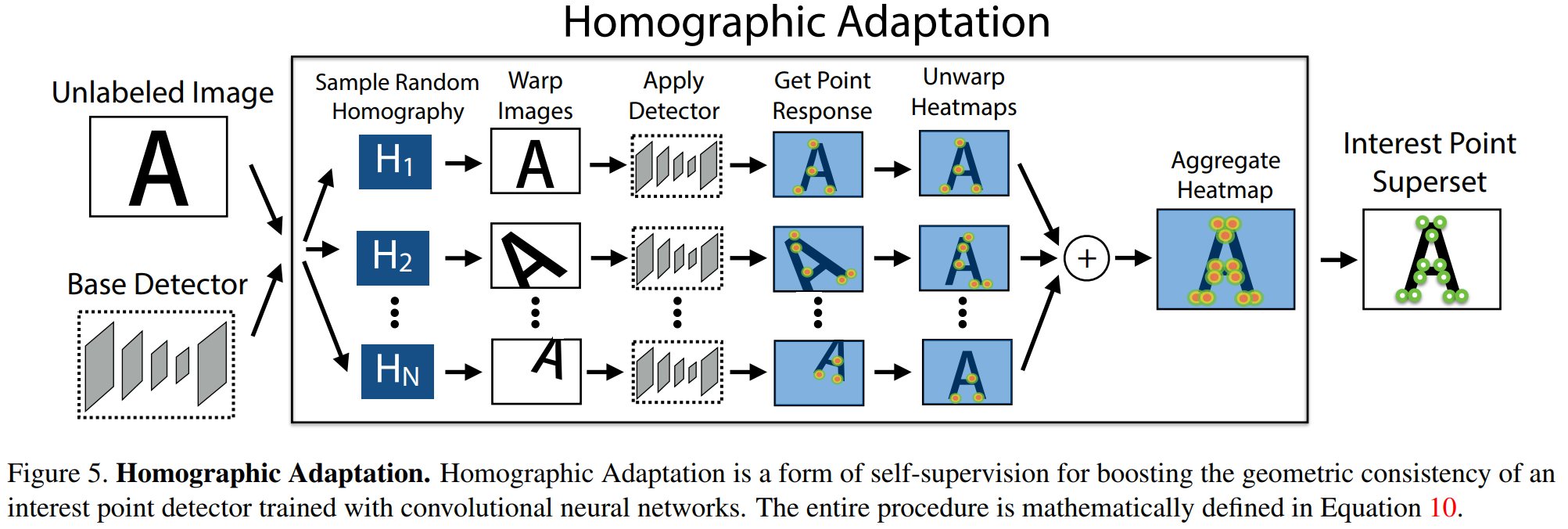
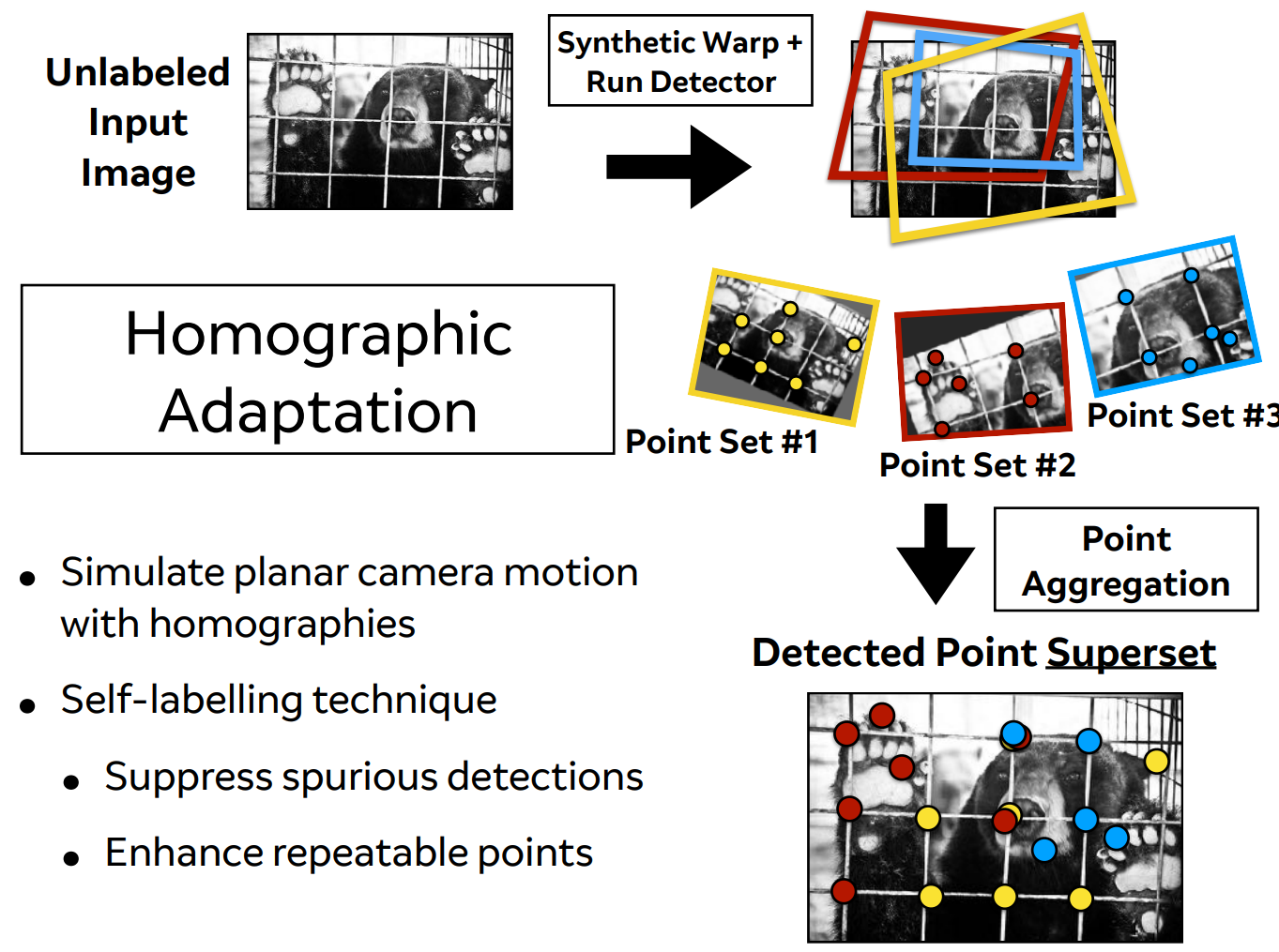
最后的关键点检测器,即,可以表示为再所有随机单应变换/反变换的聚合:
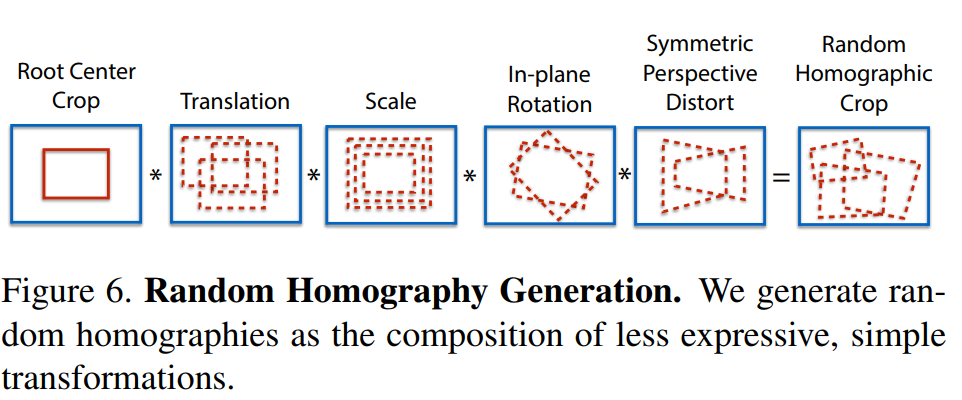
构建残差,迭代优化描述子以及检测器
利用上面网络得到的关键点位置以及描述子表示构建残差,利用ADAM进行优化。
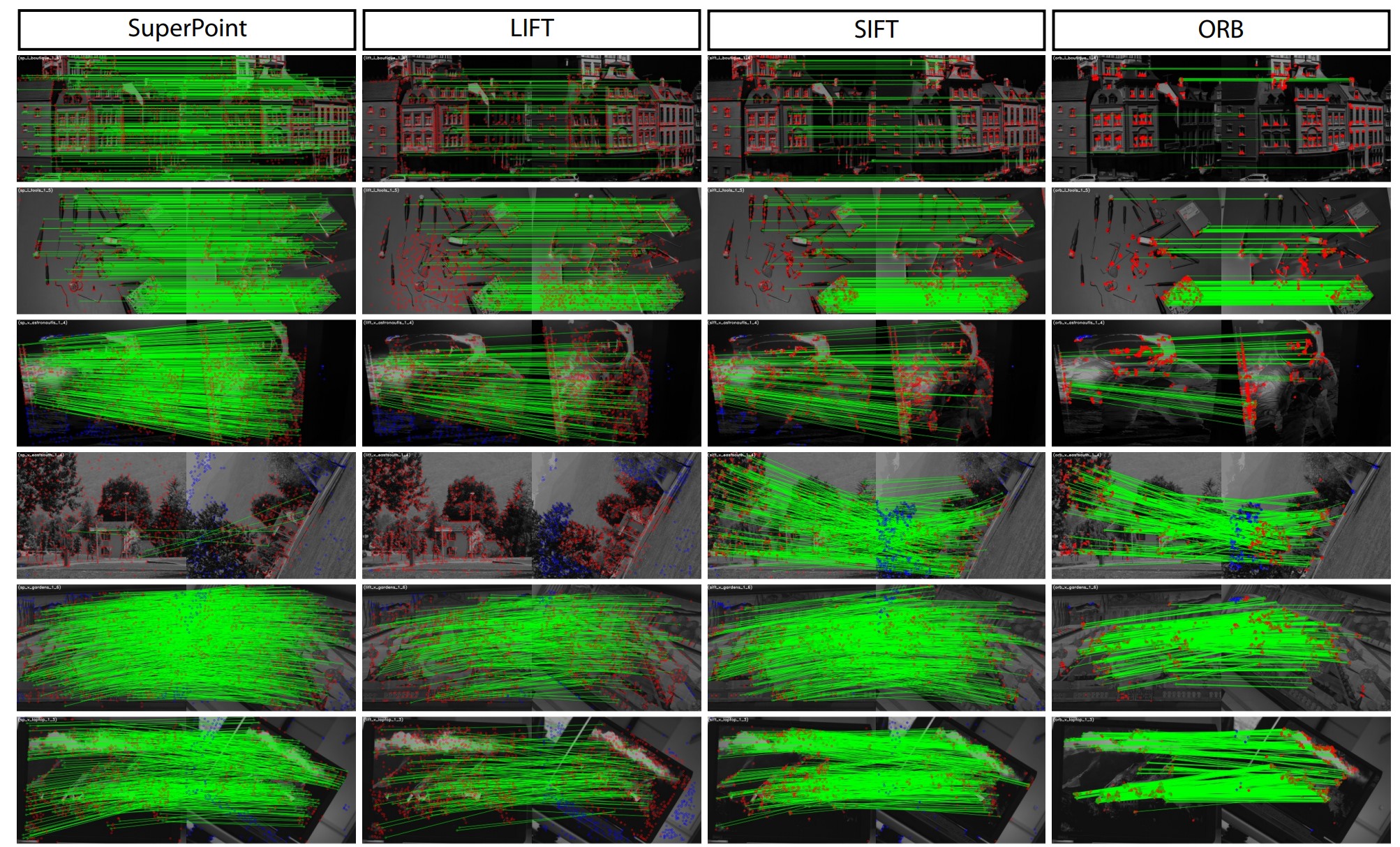
实验结果
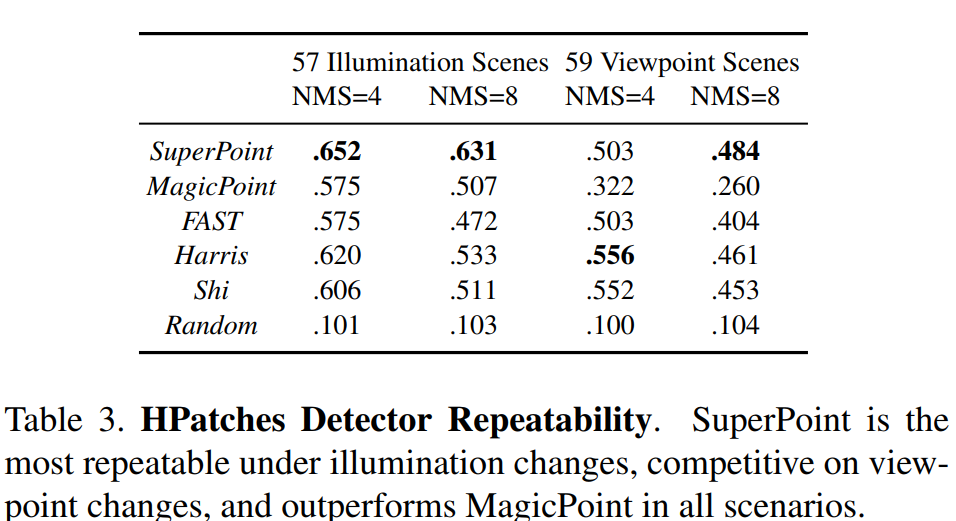
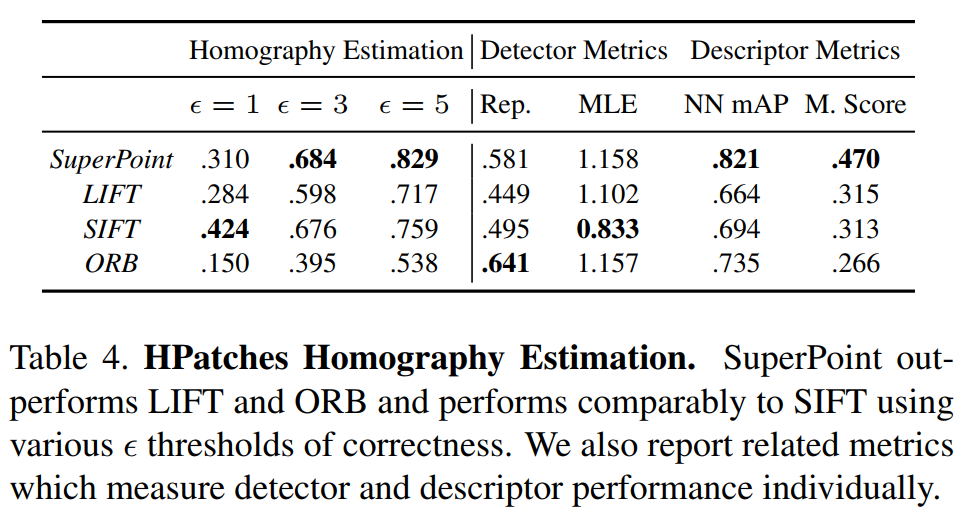
总结
- it is possible to transfer knowledge from a synthetic dataset onto real-world images
- sparse interest point detection and description can be cast as a single, efficient convolutional neural network
- the resulting system works well for geometric computer vision matching tasks such as Homography Estimation
未来工作:
- 研究Homographic Adaptation能否在语义分割任务或者目标检测任务中有提升作用
- 兴趣点提取以及描述这两个任务是如何影响彼此的
作者最后提到,他相信该网络能够解决SLAM或者SfM领域的数据关联*,并且*learning-based前端可以使得诸如机器人或者AR等应用获得更加鲁棒。
代码
以下给出的是Sarlin在SuperGlue代码中重构的SuperPoint前向推理代码,与Daniel于2018年的原始版本有些差异。不过Sarlin的版本与原版结果几乎一致,另外增加多batch的支持,执行效率更高。
# %BANNER_BEGIN%
# ---------------------------------------------------------------------
# %COPYRIGHT_BEGIN%
#
# Magic Leap, Inc. ("COMPANY") CONFIDENTIAL
#
# Unpublished Copyright (c) 2020
# Magic Leap, Inc., All Rights Reserved.
#
# NOTICE: All information contained herein is, and remains the property
# of COMPANY. The intellectual and technical concepts contained herein
# are proprietary to COMPANY and may be covered by U.S. and Foreign
# Patents, patents in process, and are protected by trade secret or
# copyright law. Dissemination of this information or reproduction of
# this material is strictly forbidden unless prior written permission is
# obtained from COMPANY. Access to the source code contained herein is
# hereby forbidden to anyone except current COMPANY employees, managers
# or contractors who have executed Confidentiality and Non-disclosure
# agreements explicitly covering such access.
#
# The copyright notice above does not evidence any actual or intended
# publication or disclosure of this source code, which includes
# information that is confidential and/or proprietary, and is a trade
# secret, of COMPANY. ANY REPRODUCTION, MODIFICATION, DISTRIBUTION,
# PUBLIC PERFORMANCE, OR PUBLIC DISPLAY OF OR THROUGH USE OF THIS
# SOURCE CODE WITHOUT THE EXPRESS WRITTEN CONSENT OF COMPANY IS
# STRICTLY PROHIBITED, AND IN VIOLATION OF APPLICABLE LAWS AND
# INTERNATIONAL TREATIES. THE RECEIPT OR POSSESSION OF THIS SOURCE
# CODE AND/OR RELATED INFORMATION DOES NOT CONVEY OR IMPLY ANY RIGHTS
# TO REPRODUCE, DISCLOSE OR DISTRIBUTE ITS CONTENTS, OR TO MANUFACTURE,
# USE, OR SELL ANYTHING THAT IT MAY DESCRIBE, IN WHOLE OR IN PART.
#
# %COPYRIGHT_END%
# ----------------------------------------------------------------------
# %AUTHORS_BEGIN%
#
# Originating Authors: Paul-Edouard Sarlin
#
# %AUTHORS_END%
# --------------------------------------------------------------------*/
# %BANNER_END%
from pathlib import Path
import torch
from torch import nn
def simple_nms(scores, nms_radius: int):
""" Fast Non-maximum suppression to remove nearby points """
assert(nms_radius >= 0)
def max_pool(x):
return torch.nn.functional.max_pool2d(
x, kernel_size=nms_radius*2+1, stride=1, padding=nms_radius)
zeros = torch.zeros_like(scores)
max_mask = scores == max_pool(scores)
for _ in range(2):
supp_mask = max_pool(max_mask.float()) > 0
supp_scores = torch.where(supp_mask, zeros, scores)
new_max_mask = supp_scores == max_pool(supp_scores)
max_mask = max_mask | (new_max_mask & (~supp_mask))
return torch.where(max_mask, scores, zeros)
def remove_borders(keypoints, scores, border: int, height: int, width: int):
""" Removes keypoints too close to the border """
mask_h = (keypoints[:, 0] >= border) & (keypoints[:, 0] < (height - border))
mask_w = (keypoints[:, 1] >= border) & (keypoints[:, 1] < (width - border))
mask = mask_h & mask_w
return keypoints[mask], scores[mask]
def top_k_keypoints(keypoints, scores, k: int):
if k >= len(keypoints):
return keypoints, scores
scores, indices = torch.topk(scores, k, dim=0)
return keypoints[indices], scores
def sample_descriptors(keypoints, descriptors, s: int = 8):
""" Interpolate descriptors at keypoint locations """
b, c, h, w = descriptors.shape
keypoints = keypoints - s / 2 + 0.5
keypoints /= torch.tensor([(w*s - s/2 - 0.5), (h*s - s/2 - 0.5)],
).to(keypoints)[None]
keypoints = keypoints*2 - 1 # normalize to (-1, 1)
args = {'align_corners': True} if torch.__version__ >= '1.3' else {}
descriptors = torch.nn.functional.grid_sample(
descriptors, keypoints.view(b, 1, -1, 2), mode='bilinear', **args)
descriptors = torch.nn.functional.normalize(
descriptors.reshape(b, c, -1), p=2, dim=1)
return descriptors
class SuperPoint(nn.Module):
"""SuperPoint Convolutional Detector and Descriptor
SuperPoint: Self-Supervised Interest Point Detection and
Description. Daniel DeTone, Tomasz Malisiewicz, and Andrew
Rabinovich. In CVPRW, 2019. https://arxiv.org/abs/1712.07629
"""
default_config = {
'descriptor_dim': 256,
'nms_radius': 4,
'keypoint_threshold': 0.005,
'max_keypoints': -1,
'remove_borders': 4,
}
def __init__(self, config):
super().__init__()
self.config = {**self.default_config, **config}
self.relu = nn.ReLU(inplace=True)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
c1, c2, c3, c4, c5 = 64, 64, 128, 128, 256
self.conv1a = nn.Conv2d(1, c1, kernel_size=3, stride=1, padding=1)
self.conv1b = nn.Conv2d(c1, c1, kernel_size=3, stride=1, padding=1)
self.conv2a = nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1)
self.conv2b = nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1)
self.conv3a = nn.Conv2d(c2, c3, kernel_size=3, stride=1, padding=1)
self.conv3b = nn.Conv2d(c3, c3, kernel_size=3, stride=1, padding=1)
self.conv4a = nn.Conv2d(c3, c4, kernel_size=3, stride=1, padding=1)
self.conv4b = nn.Conv2d(c4, c4, kernel_size=3, stride=1, padding=1)
self.convPa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convPb = nn.Conv2d(c5, 65, kernel_size=1, stride=1, padding=0)
self.convDa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convDb = nn.Conv2d(
c5, self.config['descriptor_dim'],
kernel_size=1, stride=1, padding=0)
path = Path(__file__).parent / 'weights/superpoint_v1.pth'
self.load_state_dict(torch.load(str(path)))
mk = self.config['max_keypoints']
if mk == 0 or mk < -1:
raise ValueError('\"max_keypoints\" must be positive or \"-1\"')
print('Loaded SuperPoint model')
def forward(self, data):
""" Compute keypoints, scores, descriptors for image """
# Shared Encoder
x = self.relu(self.conv1a(data['image']))
x = self.relu(self.conv1b(x))
x = self.pool(x)
x = self.relu(self.conv2a(x))
x = self.relu(self.conv2b(x))
x = self.pool(x)
x = self.relu(self.conv3a(x))
x = self.relu(self.conv3b(x))
x = self.pool(x)
x = self.relu(self.conv4a(x))
x = self.relu(self.conv4b(x))
# Compute the dense keypoint scores
cPa = self.relu(self.convPa(x))
scores = self.convPb(cPa)
scores = torch.nn.functional.softmax(scores, 1)[:, :-1]
b, _, h, w = scores.shape
scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8)
scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8)
scores = simple_nms(scores, self.config['nms_radius'])
# Extract keypoints
keypoints = [
torch.nonzero(s > self.config['keypoint_threshold'])
for s in scores]
scores = [s[tuple(k.t())] for s, k in zip(scores, keypoints)]
# Discard keypoints near the image borders
keypoints, scores = list(zip(*[
remove_borders(k, s, self.config['remove_borders'], h*8, w*8)
for k, s in zip(keypoints, scores)]))
# Keep the k keypoints with highest score
if self.config['max_keypoints'] >= 0:
keypoints, scores = list(zip(*[
top_k_keypoints(k, s, self.config['max_keypoints'])
for k, s in zip(keypoints, scores)]))
# Convert (h, w) to (x, y)
keypoints = [torch.flip(k, [1]).float() for k in keypoints]
# Compute the dense descriptors
cDa = self.relu(self.convDa(x))
descriptors = self.convDb(cDa)
descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1)
# Extract descriptors
descriptors = [sample_descriptors(k[None], d[None], 8)[0]
for k, d in zip(keypoints, descriptors)]
return {
'keypoints': keypoints,
'scores': scores,
'descriptors': descriptors,
}