📝笔记:图像匹配挑战赛总结 (SuperPoint + SuperGlue 缝缝补补还能再战一年)
2021年6月25日(晚),CVPR 2021图像匹配研讨会1(简称IMW 2021)在线上成功举行。研讨会直播总时长4个多小时,由于时差原因,笔者当晚仅看了前一个小时,困得实在不行了,又次日看了回播,随后的几天晚上陆续对整个研讨会整理了一下。

去年(2020年5月17日)我对IMW 2020 进行了介绍,当时涌现了诸如SuperPoint + SuperGlue + DEGENSAC以及SuperPoint + GIFT + Graph Motion Coherence Network + DEGENSAC令人振奋的算法。那今年相比于去年又有什么改变呢?接下来的时间,且跟我一起回顾这次研讨会。
会议PDF: slides-imw2021
目录
- 时间表
- 主题演讲
- 研讨会论文
- 图像匹配挑战赛
- 挑战赛作品报告
- IMC2021/SimLocMatch Submission
- Learning Accurate Dense Correspondence and When to Trust Them
- LoFTR: Detector-Free Local Feature Matching with Transformers
- COTR: Correspondence Transformer for Matching Across Images
- (IMC 8k+, SimLocMatch Winner) Method Towards CVPR 2021 Image Matching Challenge
- (IMC 2k Winner) IMW2021 Workshop Report
- 总结
时间表
下图是本次IMW 2021的时间表,上午是两位大佬带来的主题演讲以及两篇workshop papers,下午对挑战赛规则以及获奖算法进行介绍。

笔者将这次大会的全部视频搬运到了B站,感兴趣的同学欢迎一键三连。
Youtube用户可查看下面的链接:
主题演讲
Event cameras2 (Prof. Davide Scaramuzza — ETH Zuich, Univ. Zurich)

ETHZ RPG实验室3的带头人 Davide Scaramuzza4 教授带来了关于事件相机原理以及应用方面的主题演讲(大致看了下Slides,基本上还是CVPR 2019年的内容)。Davide教授在事件相机研究方面做了大量工作,但由于时间有限,Davide教授仅介绍了约50min。但是值得注意的是,RPG实验室在另外一个会场组织了”CVPR 2021 Workshop on Event-based Vision”5,这个研讨会召集了事件视觉方向的研究学者,非常详尽地介绍了基于事件视觉的最新进展,感兴趣的同学可以关注下这个主题。

Image matching and SfM: Classical, recent results and privacy (Prof. Marc Pollefeys — ETH Zurich, Microsoft)
来自ETHZ CVG 实验室6的 Marc Pollefeys 7 教授简短地介绍了有关图像特征匹配以及SFM的经典方法,然后介绍了他们团队最近在SFM方向有关隐私保护的相关工作。
首先 Marc 展示了他们团队多年前(2004年)做过的一项有意思的工作:从视频恢复3D模型。从展示效果上看已经很不错, 但从现在来看,这项工作还有很大的局限性,其中最大的局限性就是feature detectors。对于视频序列的帧间追踪可以用KLT,若对于非专业人员采集的图像序列,就需要对其采集过程进行约束(否则使用当时比较弱的特征提取器+描述子难以应对较大的帧间运动)。
直到出现了SIFT,做CV的应该都比较熟悉该特征具有良好的尺度不变性,这使得它目前仍然应用于多个SFM框架,如COLMAP,openMVG,openMVS等。
随后提到了基于深度学习的特征提取器+描述子D2-NET8等。紧接着是SOLD29,一种线段提取器+描述子,具体方法很大程度上借鉴了SuperPoint10。它能够在如下场景提取相比点特征更多的线特征。
接下来又讲解了Pixloc11,作者是SuperGlue的一作Paul-Edouard Sarlin12,即给定查询帧+初始粗糙的位姿以及局部地图,使用Pixloc即可优化获得其精确位姿。
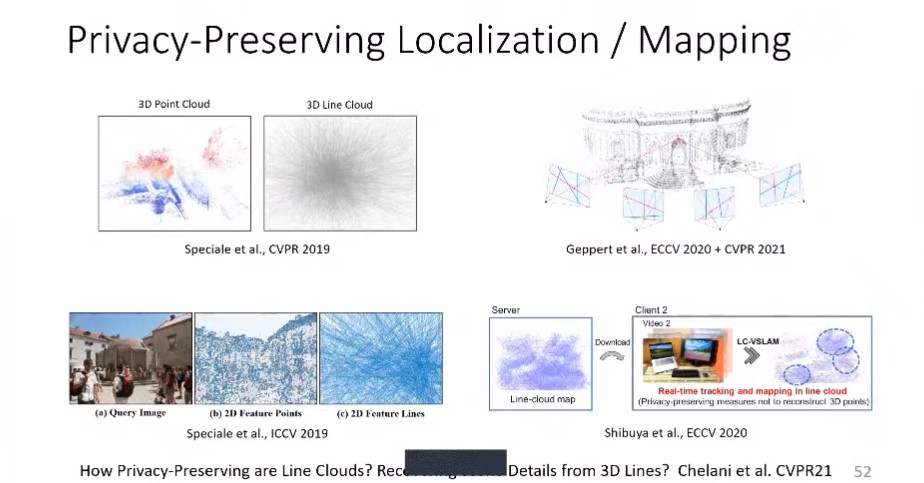
之前介绍了在SFM以及视觉定位方面的相关工作, Marc 教授接下来介绍了**“Privacy-Preserving Localization/Mapping”**相关工作。
IMW_2021_Image_matching_SfM_marc_prollefeys_14
首先是基于线段特征隐私保护的定位与建图13,这项工作发表于ECCV 2020。
紧接着是发表在CVPR 2021上的工作,“Privacy-Preserving Image Features”14
研讨会论文
Workshop paper, “Perceptual Loss for Robust Unsupervised Homography Estimation”, by Daniel Koguciuk15 (NavInfo)
摘要:单应估计是许多计算机视觉任务中不可缺少的一步。然而,现有的方法对光照和/或较大的视点变化不鲁棒。本文提出了双向隐式单应估计(biHomE)损失的进行无监督单应估计。biHomE使原视点的扭曲图像和目标视点的对应图像在特征空间中的距离最小化。本文使用了一个固定的预先训练的特征抽取器,本框架中唯一可学习的部分是单应网络,因此本框架有效地将单应估计与表示学习解耦。我们在合成COCO数据集生成中使用了额外的光度失真步骤,以更好地表示真实场景的照明变化。本文证明了biHomE在合成COCO数据集上达到了最先进的性能,这与有监督的方法相比也是相当或更好的。此外,与现有方法相比,实验结果证明了该方法对光照变化的鲁棒性。
paper: https://arxiv.org/abs/2104.10011
Workshop paper, “DFM: A Performance Baseline for Deep Feature Matching”, by Ufuk Efe16 (Roketsan & METU Center for Image Analysis)
摘要:本文提出了一种新型的图像匹配方法,它利用现成的(off-the-shelf,即预训练好的)深度神经网络提取的特征点,获得了不错的性能。本文方法使用预训练的VGG架构网络作为特征提取器,不需要任何额外的训练以改善匹配。受认知心理学领域成熟的概念启发,如心理旋转(Mental Rotation)范式,估计初步的几何变换并对图像进行初步对齐。这些估计是基于待匹配图像的VGG网络最终输出层的最近邻的密集匹配得到。在这个初步对齐之后,同样的方法在参考图像和对齐图像之间以分级的方式(hierarchical manner)再次重复,以达到良好的定位和匹配性能。在Hpatches数据集上,我们的算法在1个像素和2个像素的阈值上分别达到了0.57和0.80的平均匹配精度(MMA),这个结果比目前最先进的匹配器性能更优。
目前算法论文已开源。
code: https://github.com/ufukefe/DFM
paper: https://arxiv.org/abs/2106.07791
图像匹配挑战赛
(ReRe-)Introducing the Image Matching Benchmark (Kwang Moo Yi17)
研讨会组织者之一的Kwang Moo Yi17再次(因为2019,2020年已经介绍了)介绍图像匹配挑战赛是什么以及比赛规则等(此处略过)。

IMW_2021_Image_matching_chanllenge_1
PhotoTourism and GoogleUrban Datasets (Eduar Trulls18)
本次挑战赛共有三个数据集:Phototourism ,GoogleUrban 以及PragueParks,其中第一个数据集与2020年相同;后面两个是本次研讨会新增的。研讨会组织者之一的Eduar Trulls18前两个数据集(城市场景)进行介绍。

IMW_2021_Image_matching_chanllenge_4

IMW_2021_Image_matching_chanllenge_5

IMW_2021_Image_matching_chanllenge_6
PragueParks Dataset & Challenge Results (Dmytro Mishkin19)
组织者之一的Dmytro Mishkin19首先对非城市场景数据集PragueParks 进行介绍,这个数据集有更多野外场景图像。

IMW_2021_Image_matching_chanllenge_7
这个数据集是由iPhone11采集的视频,处理得到的24fps的图像,它有如下几个特点:
- 场景中没有人
- 多个相机焦距
- 无人造建筑
- 野外场景,更多植物
- 偶尔有运动模糊
- 高分辨率
- 真值由三维重建商业软件Capturing Reality快速获得(比COLMAP快100倍)

IMW_2021_Image_matching_chanllenge_8
介绍完数据集后,Dmytro Mishkin对挑战赛结果进行介绍。2021年图像挑战赛的规则相比于2019和2020年删除了显示描述子维度的限制。

IMW_2021_Image_matching_chanllenge_10
今年提交的数相比去年有所减少,为何降低呢?延期是主要因素(新数据集,COVID等)。另外有则轶事:今年没有那么多人使用Aachen数据集以及HPatches数据集了。

亮点
接下来就是本次挑战赛的冠亚军获得者。
无限制特征点数量组别:来自旷视科技Research 3D团队获得冠军,腾讯优图与厦大人工智能学院获得亚军。

IMC2021无限制特征点
限制特征点数量组别:腾讯优图与厦大人工智能学院获得冠军,旷视科技Research 3D团队获得亚军。

IMC2021有限制特征点
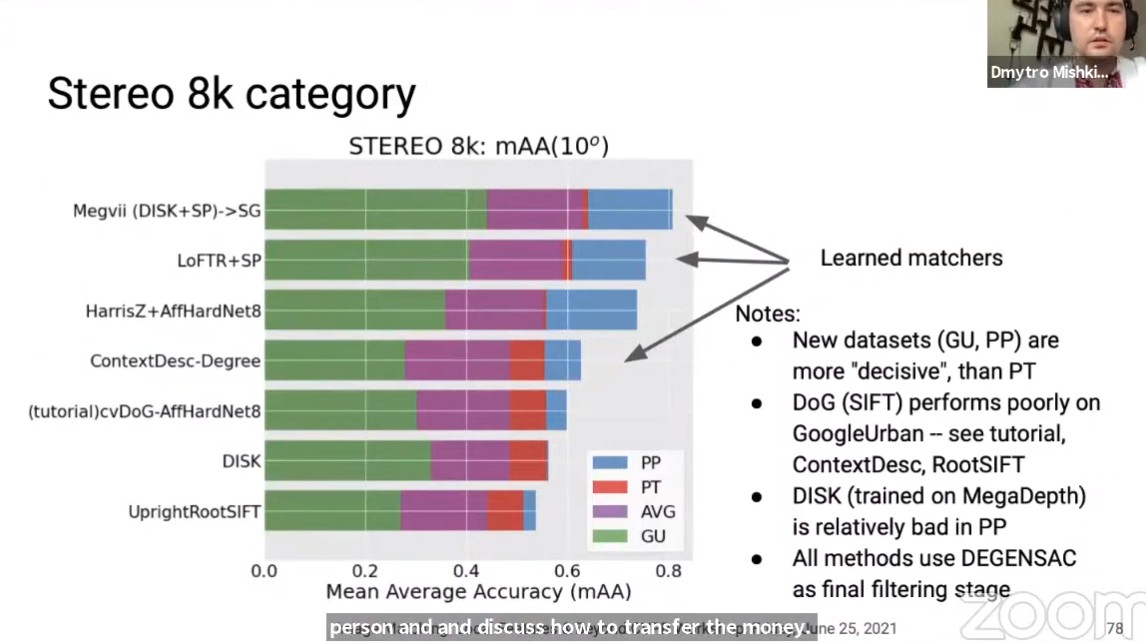
对于无限制点数量的Stereo任务,有如下特点:
- 新数据集(GU,PP)相比PT具备更好的判别性;
- DoG(SIFT)在GU上表现较差;
- DISK在PP上表现极差;
- 所有的方法最后都使用了DEGENSAC;
Stereo 8K
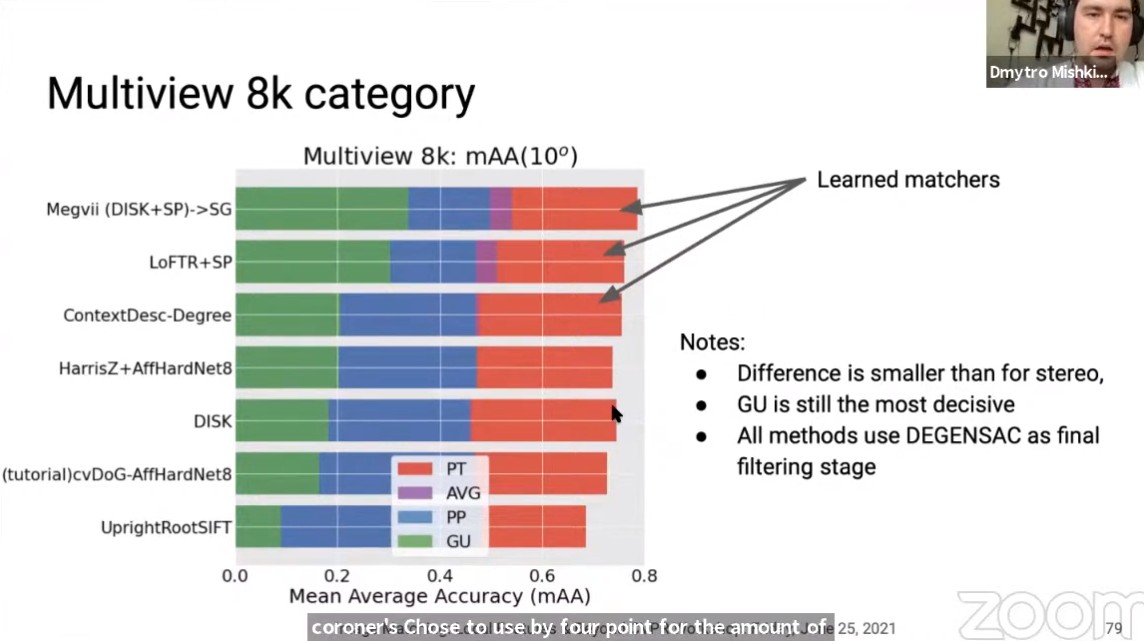
对于无限制点数量的Multiview任务,有如下特点:
- 各个算法的差异性小于stereo任务;
- GU上的判别性还是最强的;
- 前三名都使用了基于学习的匹配器;
- 所有的方法最后都使用了DEGENSAC;
Multiview 8K
对于有限制点数量的Stereo任务,有如下特点:
- 位居TOP2的算法比原始的SP+SG的提升非常小;
- DISK对于建筑物过拟合(在PP上表现非常差);
- 所有的方法最后都使用了DEGENSAC;
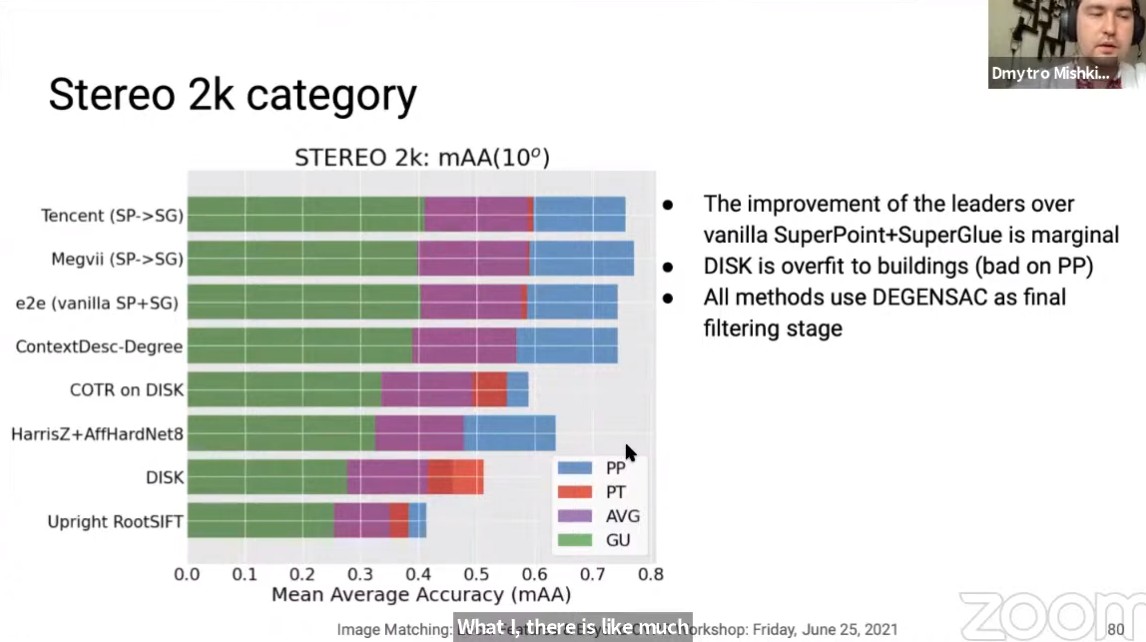
IMW_2021_Image_matching_chanllenge_16
对于有限制点数量的Multiview任务,有如下特点:
- 各个算法的差异性小于stereo任务;
- RootSIFT在GU上表现特别差;
- 所有的方法最后都使用了DEGENSAC;
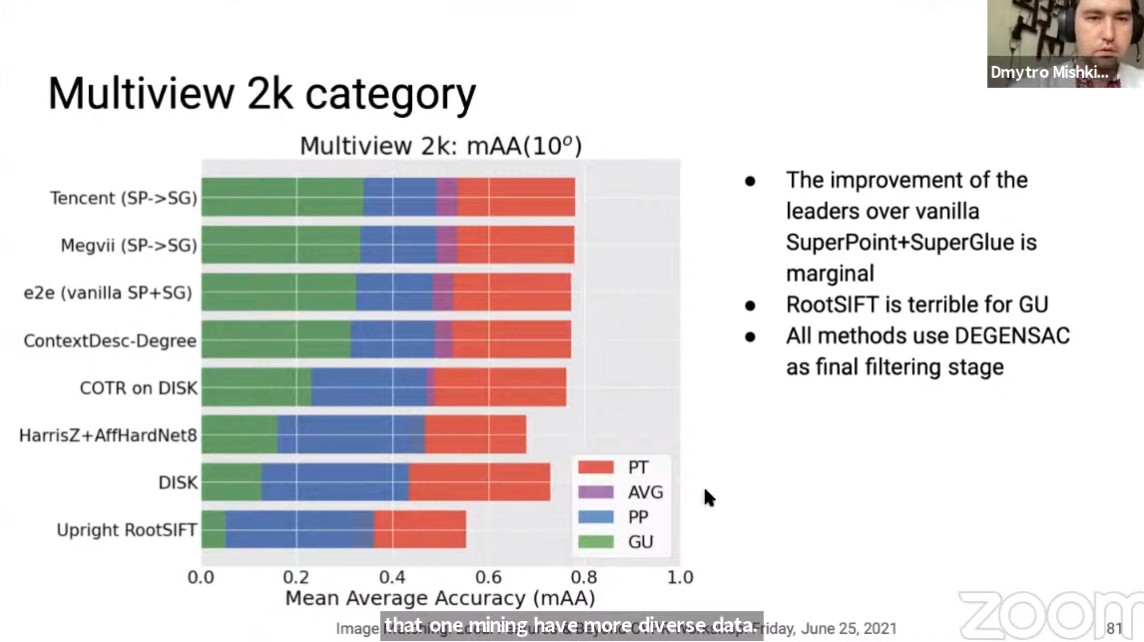
IMW_2021_Image_matching_chanllenge_17
SimLocMatch Challenge (Vassileios Balntas20)
组织者Vassileios Balntas20介绍了SimLocMatch Challenge21,并对该挑战战报进行介绍。
首先介绍了什么是SimLocMatch21。它是一个基于合成序列的数据集和基准,在不同的挑战性条件下呈现。SimLocMatch21的一个显著优点是可以获得真实和完全准确的真值。这可以对匹配方法的进行严格评估,该数据集能够获得相比使用真实数据更加准确的真值,这是使用SFM流程获得真值不具备的优势。

IMW_2021_Image_matching_chanllenge_18

IMW_2021_Image_matching_chanllenge_19
紧接着汇报了此次SimLocMatch21挑战赛的TOP3算法。第一名来自旷视研究院,第二名是商汤的LoFTR,第三名是来自巴勒莫大学和捷克理工大学的HarrisZ+。

IMW_2021_Image_matching_chanllenge_26
几点总结:
- 错误匹配仍然比较明显:
- 最优的方法如Megvii&LoFTR,匹配FP与TP的比值仍然有约10%;
- 大多数方法匹配FP与TP的比值在30%~50%;
- 还有一些方法接近无法辨识(D2NET丢人啊,快到90%了);
- 最好的基于transformer的方法匹配性能优于局部特征+基于深度学习元素的方法(HarrisZ+),但是提升并不是很大(相较于从SIFT到HarrisZ+的提升);

IMW_2021_Image_matching_chanllenge_27
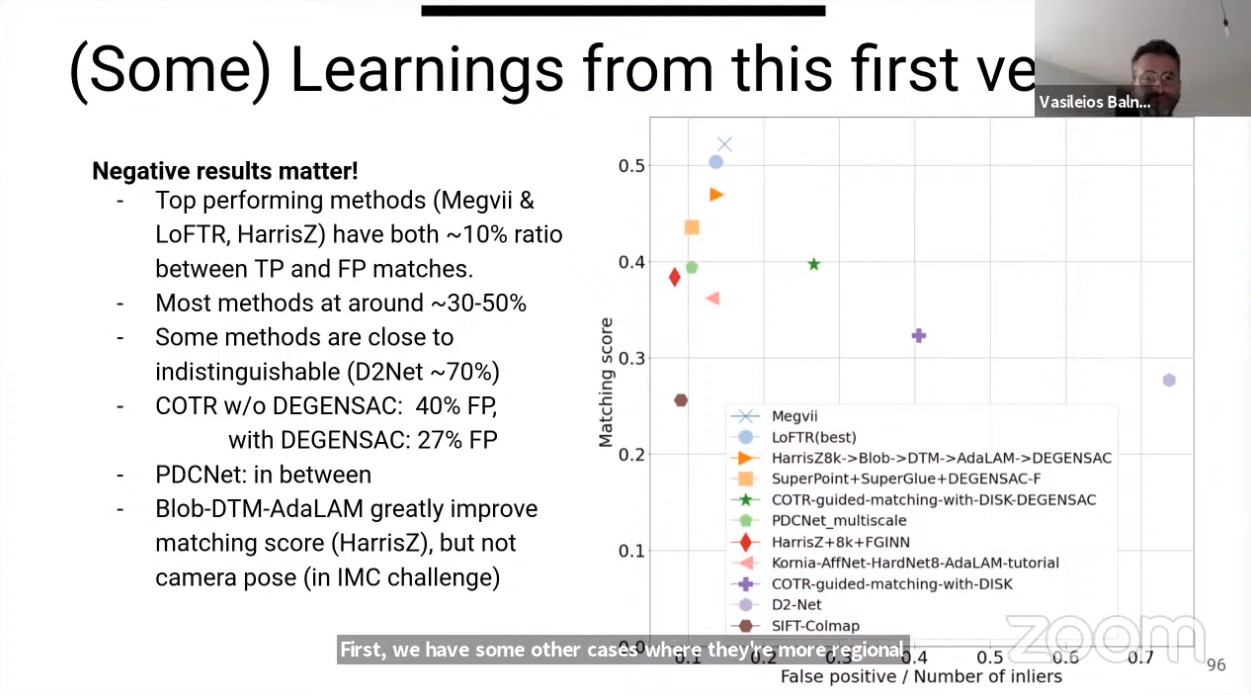
IMW_2021_Image_matching_chanllenge_28
Open Discussion
-
在PP数据集上的性能没有 达到饱和,绝大部分算法在这个数据集上表现相当,仍有提升空间;
-
几乎所有的提交算法都是用了自定义的匹配器;
-
不少打榜算法并非重磅“原创”,SP+SG缝缝补补还能撑一年!

IMW_2021_Image_matching_open_discussion_1

IMW_2021_Image_matching_open_discussion_2
挑战赛作品报告
IMC2021/SimLocMatch Submission (Fabio Bellavia)
摘要:作者介绍了一种混合使用人工设计的特征点+深度学习描述子+人工设计的匹配器的方法。首先使用了手工设计的特征点HarrisZ+提取角点,随后使用AFFNet+HardNet8计算深度学习描述子;最后使用blob匹配和Delaunay Triangulation匹配(DTM)对特征进行匹配。
paper: https://arxiv.org/abs/2106.09584
video: 3:41:40 — IMC2021/SimLocMatch Submission (Fabio Bellavia)
Learning Accurate Dense Correspondence and When to Trust Them (Prune Truong)
摘要:在一对图像之间建立稠密的对应关系是一个重要而普遍的问题。然而,在大位移或同质区域的情况下,稠密光流估计往往是不准确的。对于大多数应用和下游任务,如姿势估计、图像处理或三维重建,知道何时何地要相信估计的匹配是至关重要的。在这项工作中,我们旨在估计一个与两幅图像相关的稠密光流场,同时给出像素级的置信图,用以表明预测匹配的可靠性和准确性。我们开发了一种灵活的概率方法,联合学习光流预测和它的不确定性。特别是,我们将预测分布参数化为一个受限的混合模型,确保对准确的光流预测和异常值进行更好的建模。我们的方法在多个具有挑战性的几何匹配和光流数据集上取得了最先进的结果。我们进一步验证了概率置信估计对姿势估计任务的有用性。
code: https://github.com/PruneTruong/PDCNet
paper: https://arxiv.org/abs/2101.01710
LoFTR: Detector-Free Local Feature Matching with Transformers (Jiaming Sun)
摘要:本文提出了一种新颖的用于局部图像特征匹配的方法。代替了传统的顺序执行图像特征检测,描述和匹配的步骤,本文提出首先在粗粒度上建立逐像素的密集匹配,然后在精粒度上完善精修匹配的算法。与使用cost volume搜索对应关系的稠密匹配方法相比,本文使用了Transformers中的使用自我和交叉注意力层(self and cross attention layers)来获取两个图像的特征描述符。Transformers提供的全局感受野使图像能够在弱纹理区域产生密集匹配(通常情况下在低纹理区域,特征检测器通常难以产生可重复的特征点)。在室内和室外数据集上进行的实验表明,LoFTR在很大程度上优于现有技术。
code: https://github.com/zju3dv/LoFTR
paper: https://arxiv.org/abs/2104.00680
COTR: Correspondence Transformer for Matching Across Images (Wei Jiang)
摘要:本文作者提出了一种匹配网络,输入为两张图像以及其中一张图像中的任意一点,输出为另外一张图像上的对应匹配点。为了使用图像的局部与全局信息,同时让模型能够捕获图像区域间的相似度,作者设计了基于Transformer的网络结构。在网络实际前向推理时,网络通过迭代地在估计点周围进行缩放,这能够使该匹配网络能够获得非常高的匹配精度。该网络能够在多项任务中获得最佳效果,其中包括稀疏匹配,稠密匹配,大视角立体视觉以及光流估计。
code: https://github.com/ubc-vision/COTR
paper: https://arxiv.org/abs/2103.14167
(IMC 8k+, SimLocMatch Winner) Method Towards CVPR 2021 Image Matching Challenge (Megvii)
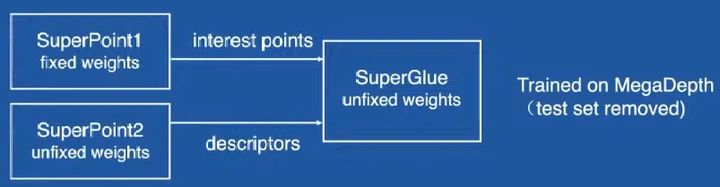
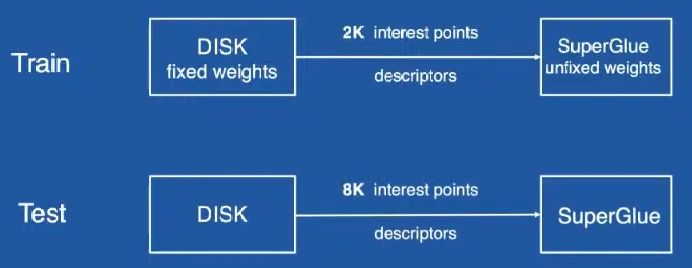
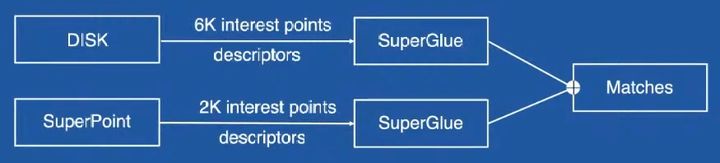
摘要:旷视团队主要是对SuperPoint + SuperGlue做了如下修改:预处理:增加掩模,不使用诸如人,车等动态物体上提取点;使用softmax函数对特征点位置进行精化,可以使特征点更加精准;另外使用了较大半径的NMS使特征点分布更加均匀。最后关键的一步特征匹配,旷视团队提供了3种思路:重新训练SuperPoint增强器描述能力;使用DISK特征对SuperGlue重新训练;联合使用上面两种方式。
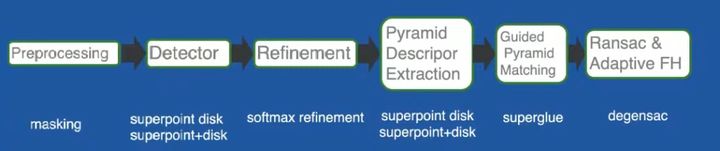
IMW_2021_Image_matching_open_discussion_2
IMW_2021_Image_matching_open_discussion_2
IMW_2021_Image_matching_open_discussion_2
IMW_2021_Image_matching_open_discussion_2
(IMC 2k Winner) IMW2021 Workshop Report (Tencent, Xiamen University)
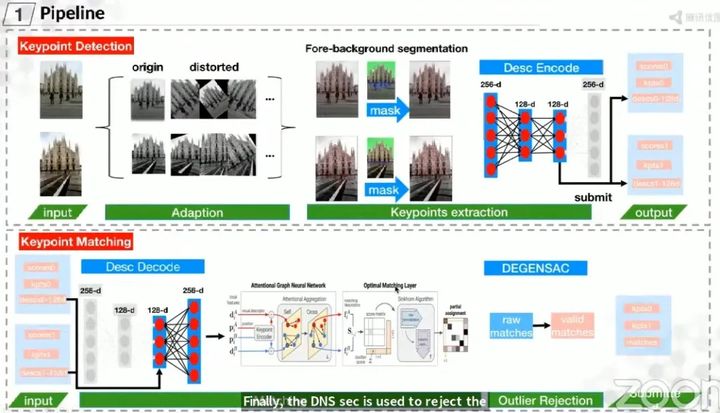
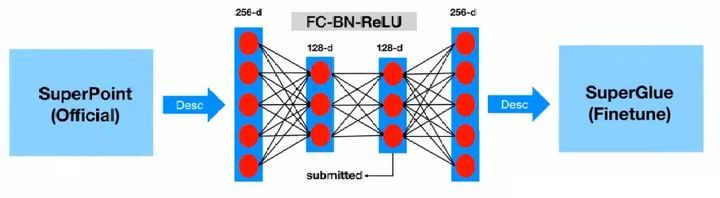
摘要:优图团队也是对SuperPoint+SuperGlue做了修改。具体地,待匹配图像对经过一系列的仿射变换(增强特征点旋转不变性)以及前/背景分割后喂给SuperPoint提取特征点以及描述子(通过一个自动编码器将描述子降维到128维);随后是特征匹配,此处还是利用了SuperGlue(为了适配SuperGlue的输入,解码器还需将128维的特征解码到256维),作者对其SuperGlue网络进行了重新训练调整参数。
IMW_2021_Image_matching_open_discussion_2
IMW_2021_Image_matching_open_discussion_2
总结
总结一下,说实话这次IMW2021并没有带来太大的惊喜,截至目前最好的(用于位姿估计)特征匹配算法还是基于SuperPoint(CVPR 2018) + SuperGlue (CVPR 2020)的变种。不过回顾整个的研讨会还是有如下几点体会:
- 特征匹配本身不再是最终目的,而是更加专注于它的下游任务,如单应矩阵估计,SFM,视觉定位等任务;之前评价特征匹配性能指标,如特征点的repeatibility,match score等已不再受到“欢迎”(顺带老牌Hpatches数据集也接近弃用);
- 基于Transformers注意力机制的特征匹配已经成为趋势,同时detector-free的稠密匹配方法也逐渐变多;二者结合能够较好处理大视角以及稀疏纹理下的图像匹配问题;
- 以前使用SFM生成的位姿“真值”不再真实,SimLocMatch 虚拟数据集似乎能够解决真值问题。但该数据集对世界的表示能力到底有多强仍值得探讨;若某个算法在该数据集表现完美之后,是否在现实场景中依旧完美?是否到最后还是陷入不可测的境地?
- 挑战数据集(GU,PP)进一步得到扩充,二者对不同算法具有更好的判别性;
- 位姿解算容易受外点影响,特征匹配的最后一步诸多算法都使用了DEGENSAC对外点进行过滤;
- 期待下一届。
Footnotes
-
ICCV 2021 Workshop on Long-Term Visual Localization under Changing Conditions, https://sites.google.com/view/ltvl2021/home ↩
-
Event Camera, http://rpg.ifi.uzh.ch/research\_dvs.html ↩
-
Robotics and Perception Group, http://rpg.ifi.uzh.ch ↩
-
Davide Scaramuzza, http://rpg.ifi.uzh.ch/people\_scaramuzza.html ↩
-
CVPR 2021 Workshop on Event-based Vision, https://tub-rip.github.io/eventvision2021 ↩
-
Computer Vision and Geometry Group, https://www.cvg.ethz.ch/research ↩
-
Marc Pollefeys, https://people.inf.ethz.ch/pomarc/research.html ↩
-
M. Dusmanu et al., “D2-Net: A Trainable CNN for Joint Detection and Description of Local Features,” May 2019. Accessed: Jun. 27, 2021. [Online]. Available: http://arxiv.org/abs/1905.03561 ↩
-
R. Pautrat, J.-T. Lin, V. Larsson, M. R. Oswald, and M. Pollefeys, “SOLD2: Self-supervised Occlusion-aware Line Description and Detection,” arXiv:2104.03362 [cs], Apr. 2021, Accessed: Jun. 27, 2021. [Online]. Available: http://arxiv.org/abs/2104.03362 ↩
-
D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self-Supervised Interest Point Detection and Description,” arXiv:1712.07629 [cs], Apr. 2018, Accessed: Jun. 27, 2021. [Online]. Available: http://arxiv.org/abs/1712.07629 ↩
-
P.-E. Sarlin et al., “Back to the Feature: Learning Robust Camera Localization from Pixels to Pose,” arXiv:2103.09213 [cs], Apr. 2021. [Online]. Available: http://arxiv.org/abs/2103.09213 ↩
-
Paul-Edouard Sarlin, https://psarlin.com/ ↩
-
Privacy Preserving Structure-from-Motion, ECCV 2020, Homepage: http://cvg.ethz.ch/research/privacy-preserving-sfm/ ↩
-
M. Dusmanu, J. L. Schönberger, S. N. Sinha, and M. Pollefeys, “Privacy-Preserving Image Features via Adversarial Affine Subspace Embeddings,” arXiv:2006.06634 [cs], Mar. 2021 [Online]. Available: http://arxiv.org/abs/2006.06634 ↩
-
Daniel Koguciuk, https://github.com/dkoguciuk ↩
-
Ufuk Efe, https://github.com/ufukefe ↩
-
Kwang Moo Yi, https://www.cs.ubc.ca/~kmyi ↩ ↩2
-
Eduard Trulls, https://etrulls.github.io ↩ ↩2
-
Dmytro Mishkin, https://dmytro.ai ↩ ↩2
-
Vassileios Balntas, http://vbalnt.github.io ↩ ↩2
-
Challenge Website2, https://simlocmatch.com ↩ ↩2 ↩3 ↩4