
题目:浅谈视觉定位(visual localization)技术 我想这个名字可能更加漂亮:visual localization revisited
本文主要内容源自NAVER LAB Europe的Martin Humenberger于2020年撰写的“Methods for visual localization”一文,本文对其进行概括并根据近两年的进展对其进行引申介绍,主要介绍了视觉定位领域的面临的主要问题,主要方法以及未来发展趋势。
背景
视觉定位(visual localization)是一种使用相机图像估计相机位姿的技术。这项技术可以用于不少基于位置(位姿)的应用如机器人、自动驾驶以及AR/MR等。众所周知Global navigation satellite systems (GNSS) (如 GPS)是一种最为常见的提供位置信息的技术,该技术已发展多年,但至今依然存在诸多限制。如室内场景、隧道场景 GPS 不可用,与此同时民用 GPS 的精度堪忧(位置误差1-2m,角度误差10度),很难满足上述应用的需求。
由于卫星定位存在上述缺点,后来研究人员尝试使用相机图像进行室内定位以及室外高精定位。例如,自动驾驶领域,车载摄像头能够提供非常丰富的视觉信息,这些信息作为查询图(query image)可以与提前构建好的视觉地图数据库进行数据关联。此处的视觉地图可以是3D重建结果(3D点以及描述子,带有位姿的相机图像、2D点信息)、带有位姿的相机图像以及深度学习模型。查询图借助已经构建好的数据关联可以解算出其相对于“世界”的位姿。
注意视觉定位(Visual Localization, 后简称VLOC)与同时建图与定位(Simultaneous Localization and Mapping, SLAM )技术的相似与不同点。 前者是一种基于地图的定位(map-based localization)算法,其特点在定位而非地图,定位是指仅给定一幅图像,通过某种方式使用地图信息解算出拍摄这幅图像的相机6DoF位姿;此外,上文已经提到,其输入是一幅图像,不再依靠其他传感器(如IMU,GPS等)信息辅助定位;地图可以由SFM(structure-from-motion)或者由SLAM得到,但由于SFM生成的地图精度较高,相机在更高精度的地图中定位的精度会更高,所以实际中的建图算法主要采用SFM(如COLMAP,OpenMVG,OpenSfM等)。而SLAM的特点在于同时建图与定位,即在实时感知环境的同时定位相机在的环境中的位姿,为了达到实时性的要求,采用了局部BA,追踪局部地图,滑动窗口优化等策略;为满足精度要求,除使用相机图像数据,还可以使用IMU,GPS,LiDAR多等传感器数据,该部分非本文重点,不做展开。
下表展示了SLAM/SFM/VLOC的差异点(展开说Todo)。
| Approach | SLAM | SFM | VLOC |
|---|---|---|---|
| full-name | Simutinously Localization And Mapping | Structure from Motion | Visual Localization |
| inputs | image / IMU / GPS etc. | image (+GPS) | image only |
| map | online | offline | offline SFM |
| speed | fast (realtime) | slow | fast |
| accuracy | middle | high | high |
| method | ORB-SLAM, VINS, GVINS, LOAM | COLMAP, OpenMVG, VisualSFM, Meshroom, CaptureReality | HLoc, Kapture, Inloc, Pixloc |
| datasets | Euroc, TUM VI | - | Aachen Day-Night, CMU seasons, RobotCar |
视觉定位的挑战
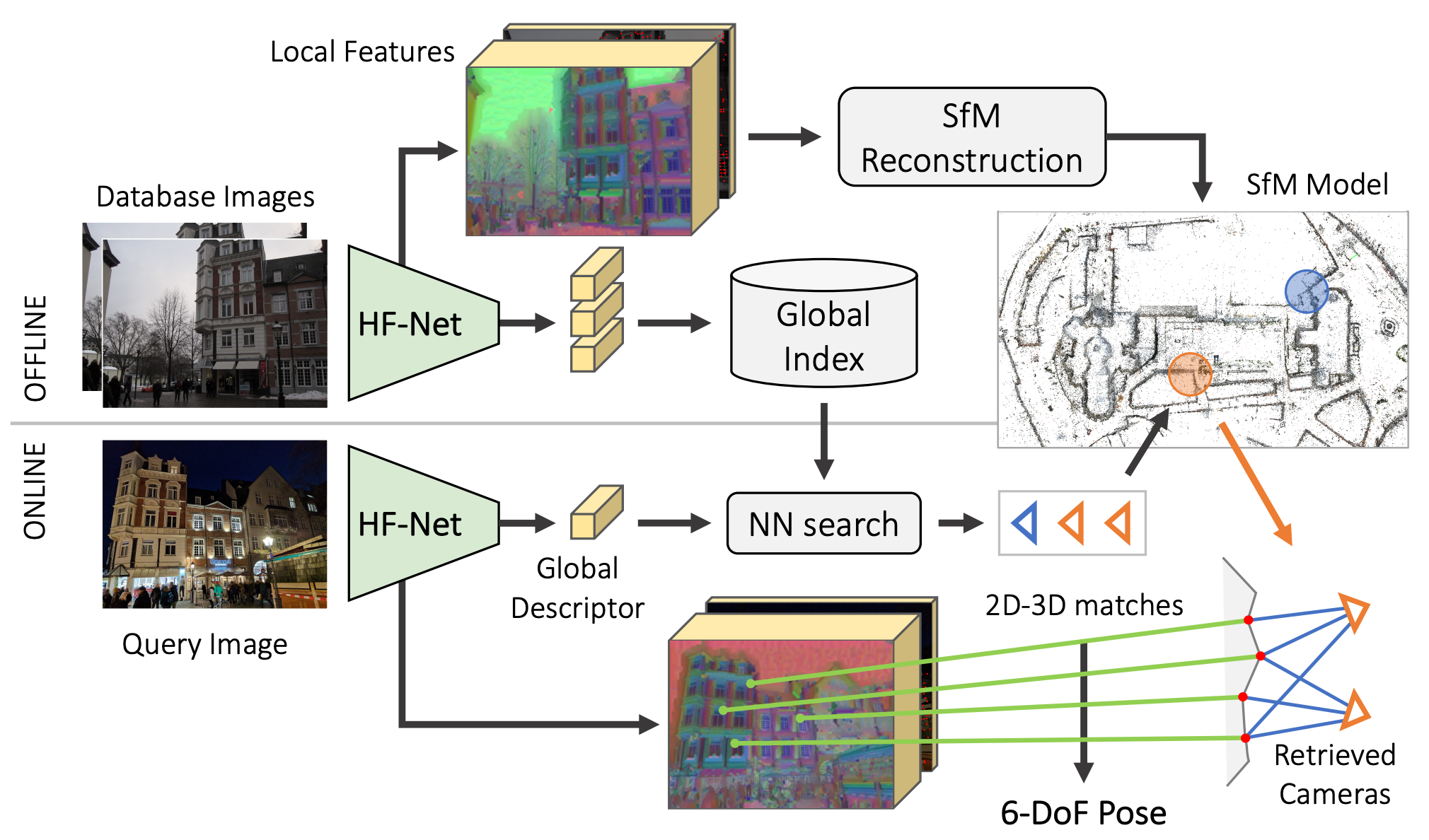

基于视觉信息的定位技术存在如下难点或者挑战:
- 光照变化;如建图时使用了白天的图像,而定位(查询)时使用的是晚上的图像,二者在图像外观上有比较明显的差异,而这种差异对于数据关联而言是较为困难的;
- 动态场景;比如说自动驾驶场景中的行人汽车等运动的非静态场景对于定位而言可能存在一定影响;
- 季节变化;比如说夏天建图,冬天定位,这种情况下场景同样也出现了较大的外观差异,势必影响;
- 视角变化;比如说查询图像与建图图像之间存在一定的视角变化,导致二者数据关联数量降低,定位精度势必降低;
- 物体遮挡;人以及物体等对场景的遮挡,这一点与动态场景类似,但并非完全一致;这一点强调的是查询图与静态场景的数据关联由于遮挡减少;

因此,目前有不少数据集用于评估不同定位算法在上述挑战场景中的表现。例如视觉定位挑战基准 The Visual Localization Benchmark,该基准中包括不同季节、光照等因素的数据集以及众多在这些数据集中的评分。另外,随着视觉定位领域的火速发展,我们可以在线找到非常多有用的资料,例如Torsten Sattler等人组织的Large-Scale Visual Localization系列课程,非常值得学习。最后,由于目前存在着大量的数据集,它们并不是同一个研究机构或者公司公开的,所以它们采用了不尽相同的数据格式,研究者在处理这些数据集时存在一定的阻力,为了解决这个问题,Kapture应运而生,借助这个工具可以比较方便地对多种数据集数据格式进行转换以及将不同的视觉地图格式之间进行转换(比如说COLMAP到OpenMVG或者相反)。
方案介绍
迄今为止,有非常多的算法用于解决视觉定位中存在的难点,下图非常概括地给出了视觉定位的方案。
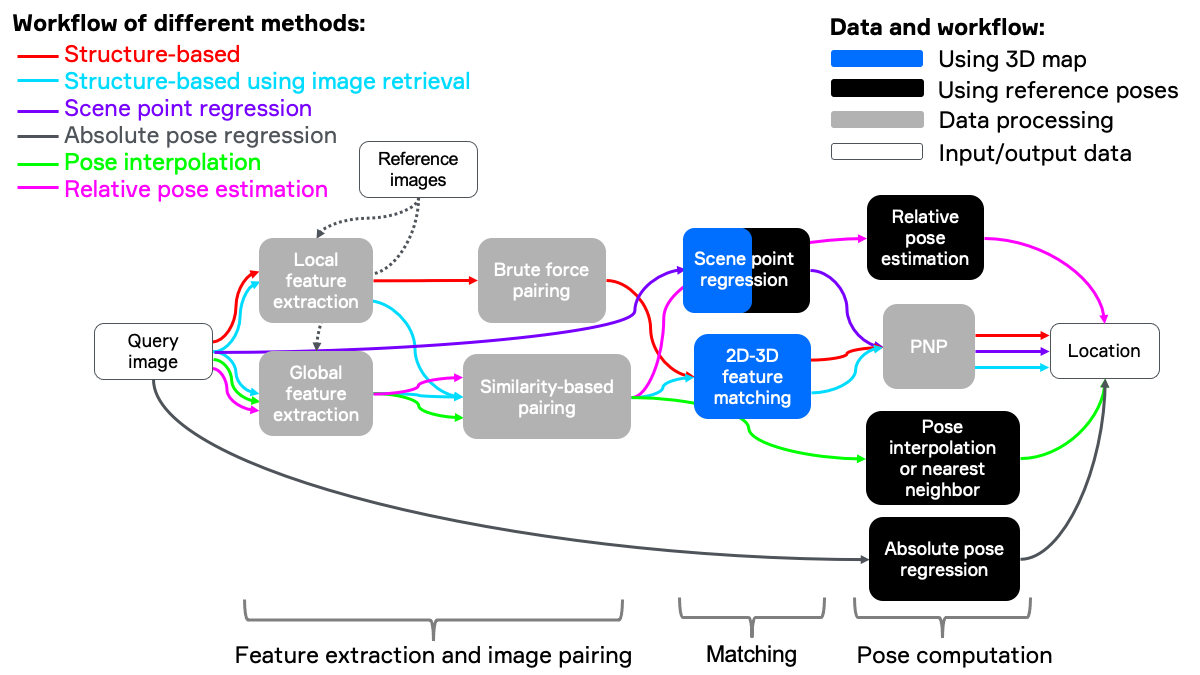
最为经典的方式是基于结构信息的定位方法(structure based),此处的结构信息可以理解为场景的3D结构,如场景的3D点云地图信息,通过构建查询图局部特征与地图点云之间的数据关联对相机进行定位。但是当地图比较大时,这种非常直接一步关联方式的效率就会变得非常低,此时可以借助图像检索(image retrieval)减小地图匹配的规模,提高定位效率,这种方式称为层次定位(hierarchical localization 或者 structure based using image retrieval)。另外一种方式是直接使用图像检索的结果进行定位,如对 top k 召回帧位姿加权,可见这种方式并不需要地图的结构信息,定位速度取决于图像检索效率,一般情况下非常快,但位姿精度并不准确。此外,场景点回归(scene point/coordinate regression)也是视觉定位中进来较火的研究领域,这种方式可以通过神经网络直接学习到2D像素位置与3D点之间的数据关联,之后采用与基于结构的方法类似的算法(如PNP1)解算位姿。目前场景点回归算法会使用场景的3D点用作训练,但在推理时并不需要。最后,绝对位姿回归(absolute pose regression)是一种使用神经网络进行端到端学习相机位姿的算法。
再来回顾一下,我们可以得到如下表格。这些方法在泛化能力以及精度上存在一定差异。此外,一些方式依赖3D地图而有些方法仅仅需要带有位姿(pose-tagged)的相机图像即可。使用场景的3D重建的信息的优势在于,位姿的精度可以做到非常高;劣势在于有些情况下场景的3D结构较为难以获取以及较难维护,如场景变化后的场景模型更新较为复杂。
| Approach | 3D map | Pros | Cons |
|---|---|---|---|
| Structure-based | yes | Perform very well in most scenarios | Challenging in large environments in terms of processing time and memory consumption |
| Structure-based with image retrieval | yes | Improve speed and robustness for large-scale settings | Quality heavily relies on image retrieval |
| Scene point regression | yes/no | Very accurate position in small-scale settings | To be improved in large environments |
| Absolute pose regression | no | Fast pose approximation, can be trained for certain challenges | Low accuracy |
| Pose interpolation | no | Fast and lightweight | Quality relies heavily on image retrieval and only provides a rough pose |
| Relative pose estimation | no | Fast and lightweight | Quality relies heavily on image retrieval and, e.g., local feature matches or a DNN used for relative pose estimation |
接下来针对上述提及的每种方法进行介绍。
基于结构信息的方案(structure based)
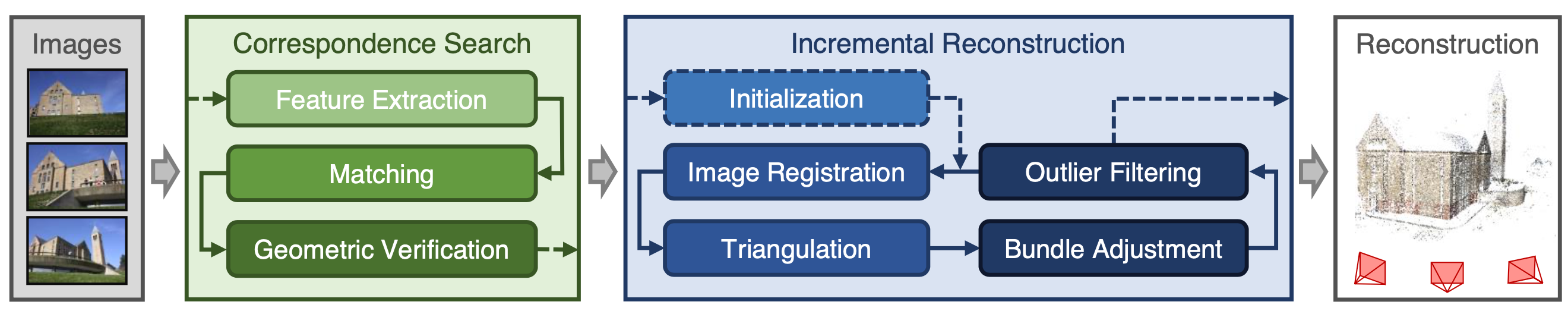
前文中已经提到,这是一种最经典的用于相机定位的算法。这种算法需要提前建好场景的3D地图,然后使用相机拍摄的图像来定位相机位姿2 3 4 5 6 7。场景地图的构建包括数据库相机图像位姿估计以及输出3D模型,此处的数据是指在同一个场景中不同位置以及角度拍摄的一系列图像, 完成地图构建的算法为structure from motion (SFM) 3 7。首先图像对(图像俩俩匹配或者根据外观相似性选择相似的图像匹配)进行像素级的局部特征匹配8 9,随后进行几何校验过滤错误匹配,经过这个过程之后可以得到场景图(scene graph),该场景图记录着图像之间的连接关系。随后使用诸如对极几何解算位姿并进行三角化 (triangulation)地图点,具体过程可以参考COLMAP7。

注意到上述数据关联中提到的局部特征,它是由图像中像素或者亚像素级别的坐标点以及用以描述该特征的描述子组成。早期的特征提取器是由人工精心设计的,如非常经典的的 SIFT10(它不止包括特征提取器,也包括描述子)。但是 SIFT 这种人工特征存在比较明显的缺陷,如对光照变化、季节变化等因素较为敏感,此时的特征匹配性能不佳。如今,数据驱动的端到端学习的局部特征 R2D2 9,D2-Net11,SuperPoint12,Key.Net13,SuperGlue14(准确来说,SuperGlue是一种特征匹配器) 等被提出,在上述挑战场景中的表现远超传统特征(文献8 15 16 中介绍了局部特征的发展过程)。
需要注意的是,构建好的定位地图中的3D点不仅包含其3D坐标,也关联着其描述子(一个3D点可能关联着多个建图时的2D局部特征,也就是说它可能有多个描述子,可采用求均值或者其他加权的方式得到3D点的描述子,todo: 补充一下描述子聚合的方式)。查询图像的2D点与地图的3D点通过描述子进行数据关联(KNN匹配)。一旦有了2D-3D匹配,查询相机的位姿可以通过perspective-n-point (PNP) 1算法进行求解。由于2D-3D可能存在外点(outliers),PNP通常以RANSAC17 18的方式进行以提升位姿解算鲁棒性。
现代RANSAC发展较快,如 MAGSAC19, MAGSAC++20,DEGESAC 等针对原有RANSAC无法有效应对外点率较大的情况,目前最先进的RANSAC算法可以在内点率非常低时求解出model。Dmytro Mishkin 等人在CVPR 2020 开展了 RANSAC tutorial,如下视频是该教程。
不难想象,当场景非常大时地图会变得非常巨大,如用于视觉定位的数据集Aachen-Day-Night 21 中包含70W~250W个3D点(不同数量的图像对得到的3D点数量也不同),然而这仅仅是德国亚琛老中城的一个小片区,如果将其范围扩展至整个城市,3D点的规模会变得非常巨大。可以想象,当在如此巨大的场景中进行2D-3D数据关联会变得非常慢,Torsten Sattler等人提出了Active Search22 23使用了一种基于词袋的方式进行匹配加速并设计了一种匹配优先级策略得到更多的2D-3D匹配对。
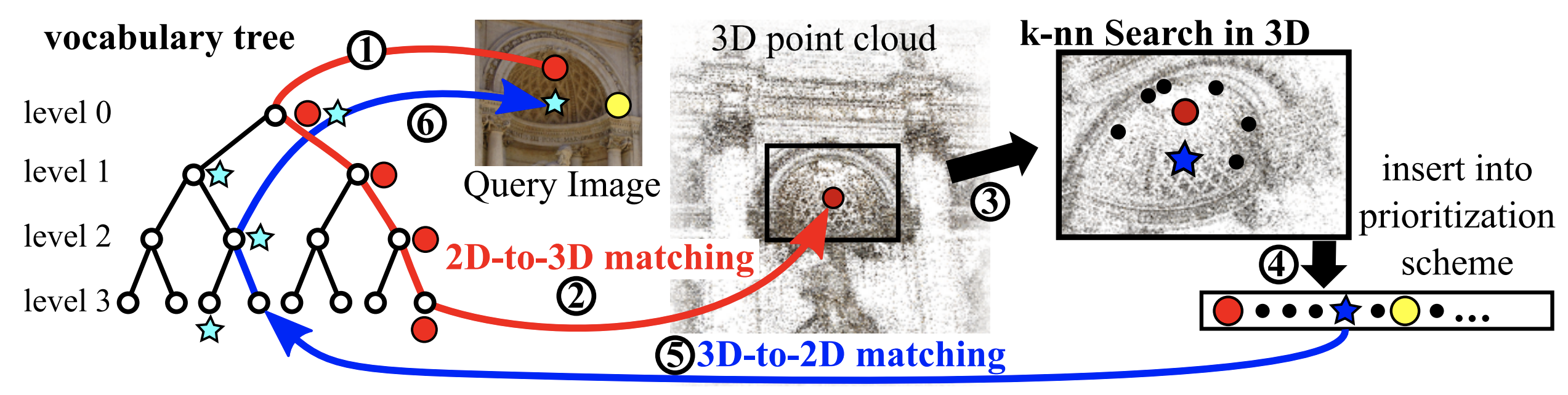
对于数据库的路标点,我们将其3D描述子通过离线的方式“分配”到视觉字典中;对于每一查询帧,我们采用同样的方式将其2D描述子“分配”到视觉字典中。于是我们可以得到图像上每个2D特征点的候选匹配点(3D),此时每个2D点可能有多个候选的3D匹配,根据候选匹配点的多少按照升序进行排列。具体的,对于每一个特征 f,遍历隶属于同一个单词内的2个最近邻,如 p1, p2,之后根据ratio-test决定该匹配是否有效。但Sattler等人认为,视觉字典其实会引入“量化误差”,该误差会限制2D-3D匹配数量。为了应对这个问题,一种通用的做法是将一个特征分配到多个单词,但作者设计了一种更加高效的策略 “Active Search”(ECCV 2012), 这个算法的基本思想是:一旦某个特征f与某个路标点p被确定为匹配对,那么处在p邻域的路标点( $N_{3D}$ 个点)同样可能被查询图像观测到。于是作者设计了一种3D-2D匹配方式,即主动地寻找p邻域中的路标点( $N_{3D}$ 个点)与图像中的2D特征点的匹配关系。

其算法流程的伪代码如上图所示:其中 $p’$ 表示 $p$ 邻域中的某个3D点, $D(p’)$ 表示该点的描述子(可能有很多个), $F$ 表示的查询图上的特征, $l$ 表示字典树的第 $l$ 层, $C$ 表示匹配对集合; $f_1,f_2$ 表示图像中的特征,AW表示activate visual words,AW记录了 $p’$ 不同的特征描述子隶属的单词(及其所在的层数);对于每一个AW记录的单词 $w$ ,同样获得图像特征中属于该单词 $w$ 的特征们 $F(w)$ ,接下来就是遍历所有属于该单词的3D特征描述子 $d$ 与图像特征 $f$ 之间的距离,记录两个最小距离 $dist_1, dist_2$ 以及对应的图像特征 $f_1,f_2$ ;随后使用 $ratio-test$ 判定该匹配是否有效;如果有效且原有的匹配集合中没有包含该匹配则加入该匹配关系;若原有匹配集合已经包含该匹配,则进一步判断,如果2D-3D匹配中没有该匹配则根据描述子距离是否更小进行替换。(这个过程有些类似于词袋匹配,不过此处是针对2D-3D匹配进行的设计)
此外,基于图像检索的方式会进一步加速该匹配过程,即首先检索全图中与查询图最接近的区域,随后查询图与该区域进行数据关联24 25,更为详细的介绍见后一小节。
另外一种构建2D-3D数据关联的方式是使用 scene point regression,其中的2D-3D 数据关联可以由DNN26 27 28 29 或者随机森林30得到。
SFM 建图
基于结构信息的定位技术非常依赖于视觉地图信息,接下来针对基于SFM的建图技术进行简要介绍。
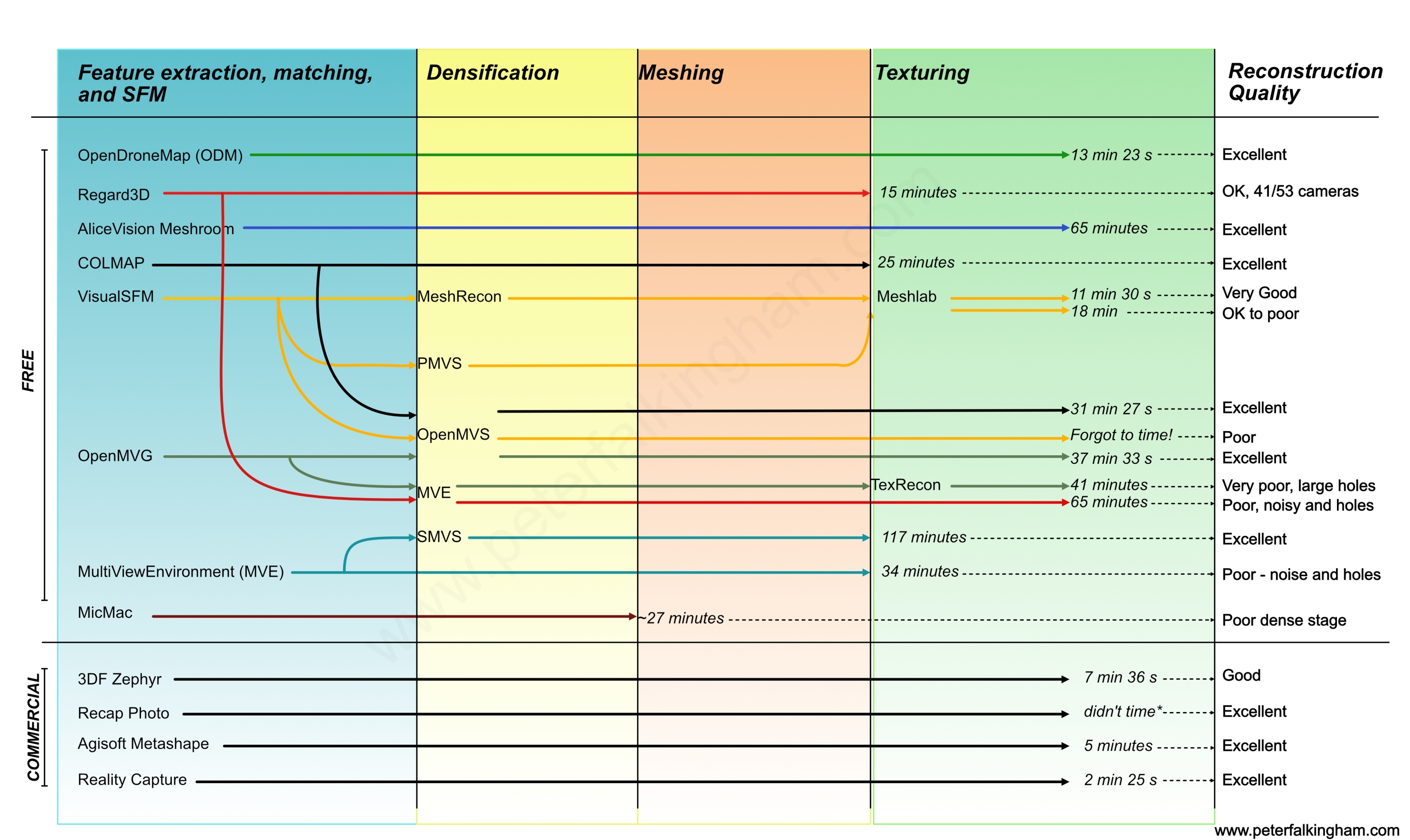
上述表格列举了SFM以及MVS的算法比较,虽然种类繁多,但目前使用最为广泛的是Johannes等人于2016年提出的COLMAP。SFM的流程可以概括为:首先进行特征提取/匹配以及后续的几何校验滤出外点,经过上述步骤可以得到所谓的场景图(Scene Graph),该场景图是后续的增量式的基础(提供数据关联等信息)。增量式重建中需要非常仔细地挑选两帧进行重建,在图像进行注册(即定位当前帧在地图中的位姿)之前,需要进行三角化场景点/滤出外点以及BA优化当前的模型。更为详细的介绍见笔者写的阅读报告(CODE, PDF),此处不再赘述。
不过现有对SFM经常会面对诸多问题:
- 重复场景下特征关联异常,导致相机错误注册;
- 特征点提取误差的存在导致点云质量不高;
- 大场景的建图效率低;
- TODO:补充目前SFM面临的问题
为了应对建图过程中重复场景(歧义)带来的相机错误注册的问题,来自CVG实验室的 Lixin Xue 基于COLMAP实现了目前几种应对该问题的建图方案 sfm-disambiguation-colmap,如下图所示的是原版COLMAP与修正错误注册后相机位姿以及场景点云,此时使用的修正异常注册算法为 ReliableResectioning。

其基本思想是:由于相似的外观在不同视角经常出现,所以此时极其容易导致这些重复特征有较长的track-length,因此作者在建图过程选择下一帧时设计了新的选择策略,即给long-tracks特征较小的权重,而short-tracks特征较大权重,用于计算两张图之间的“歧异度调整匹配”(ambiguity-adjusted match, AAM,越大越好),优先注册非歧义的那些图像。

此外,由于2D点提取误差的存在,导致SFM重建得到的3D点云位置不够准确,并随着3D点越远(深度越大),该误差越大。为应对该问题,Sarlin 等人提出了 pixel-perfect-sfm (PDF)。

Sarlin 认为,在 3D 重建任务中,跨视角的可复检的特征点检测尤为重要。原有的 SFM 框架中(COLMAP),特征提取之后其位置并不会发生改变,若这个过程中出现了一定误差,势必造成后续几何结构的误差累计。于是作者针对以上 SFM 框架中的两个步骤进行了优化:1. 特征匹配后使用 Featuremetric 对特征点位置进行优化;2. 增量重建过程中通过类似的 Featuremetric 进行 BA(重投影误差变为 Featuremetric 误差)。该算法通过定量实验验证了其在 SFM 任务中的优势。
![]()
上图展示了 pixel-perfect-sfm 算法优化框架,它可在任何基于局部特征点的SFM流程中使用,首先使用CNN提取图像特征图(dense features),根据稀疏的特征匹配得到初始的tracks,调整每一个track对应的特征点在图像中的位置;根据调整后的位置进行SFM重建,重建过程中的BA优化残差由重投影误差变为Featuremetric误差,关于本文更加详细的解读参考链接。
TODO
此处待补充视觉建图任务中存在问题的解决方案。
基于结构信息+图像召回方案(structure based using image retrieval)
这种方式也就是所谓的层次定位(hierarchical localization)方案。简单来说就是该算法将定位过程分成两步,第一步是图像召回(检索),第二步类似于使用结构信息定位。第二步与上一节内容一致,此处省略,本节重点介绍图像检索在视觉定位技术中是如何使用的。
概念

图像召回(检索),是从一系列图像数据库中以某种准则挑选出与查询图像最为相似的图像,通常在做完图像检索之后还会加一个重排序步骤(re-ranking,如query- expansion)。在视觉定位任务中的图像召回(检索),按照召回标准可以被解释为查询帧(query)“看到”了与数据库帧(database)相同的场景(如,某栋建筑、地标),即我们通常讲的路标识别(landmark retrieval)或者数据库图像在查询图像拍摄地点附近拍摄的,并不一定“看到”相同的场景,这种召回标准叫做地点识别(geo-localization/place recognition )。二者的差异可以通过上图进行说明,其中 $I_q$ 为查询图像,$I_1$和$I_3$为landmark retrieval,因为3张图像中包括相同的场景Aachen Cathedral。$I_1$ 和 $I_2$ 为geo-localization,因为这两张图距离 $I_q$ 的拍摄地很近,尽管图像外观并不相似,但在地理坐标是比较接近的。
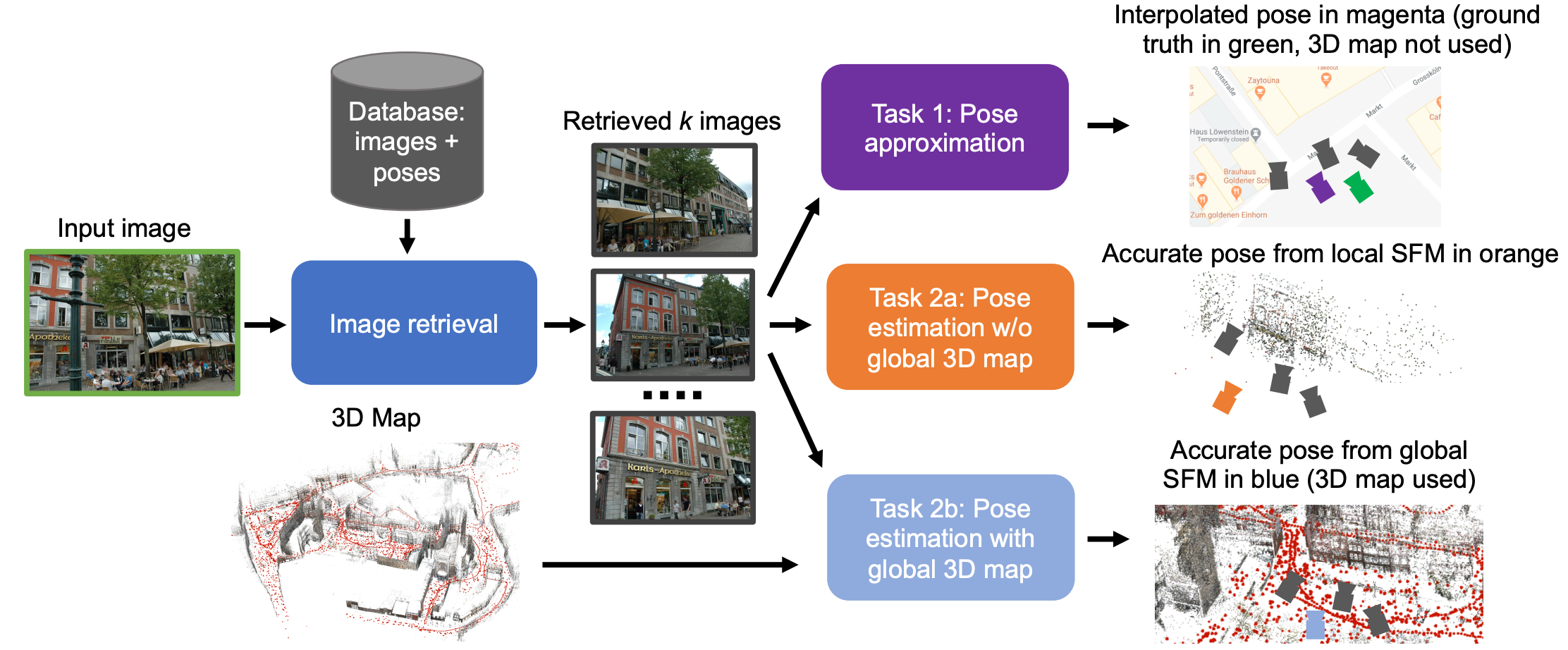 ref: Benchmarking Image Retrieval for Visual Localization, https://arxiv.org/pdf/2011.11946.pdf
ref: Benchmarking Image Retrieval for Visual Localization, https://arxiv.org/pdf/2011.11946.pdf
功能
图像召回让视觉定位能够在超大场景中定位成为可能,同时可以使建图定位更加鲁棒(重定位)。之所以可以做的这一点,是因为图像召回可以非常显著地减小视觉定位的搜索空间,即查询图需要与多大范围地图的进行关联,有了图像召回,可以将这个范围缩小,降低数据关联耗时。此外,仅仅使用召回的图像(无需建图)也可以直接进行定位,即选择使用top k召回图像进行位姿加权31 32, 这要求在存储图像时,需要同时存储拍摄图像时相机位姿信息或者GPS地理坐标。此外,若已知相机内参,查询帧与召回的参考帧之间的相对位姿就可以非常方便地通过局部特征关联解算出来。此外,当已知召回的参考帧绝对位姿,那么查询帧的绝对位姿就可以通过上述相对位姿推演出33 34。
算法
过去十年,图像召回算法使用最多的是基于词袋(bag of words)的表示,但目前图像召回使用最多的是基于深度学习的方式35 36,这是由于深度特征中对图像的高层级的语义特征进行了编码(encode),这些信息非常适合用作图像召回任务。当网络使用ranking loss37 38 39专门对图像召回任务进行训练后,召回性能可以进一步得到提升。文献40 中介绍了一项关于图像召回在视觉定位任务中基准测试。作者在3个定位任务(使用全局3D地图,在线构建局部3D地图以及位姿插值)中评价评价了4种常见的图像表征方式。
国际顶级视觉会议 ICCV 从2014年至今开展了多次关于场景识别与视觉定位相关任务的介绍,这是2021年开展了的 Large-Scale Visual Localization Tutorial,其中 Giorgos Tolias进行了 Image Retrieval & Visual Representation 的介绍,内容较为详细,推荐一看。
下文对图像检索算法进行介绍。
视觉定位任务中图像召回(检索)通常是指实例级的检索IIR (Instance leval Image Retrieval),与之对应的是类别级图像检索CIR (Category leval Image Retrieval)。前者表示检索特定的图像,如埃菲尔铁塔、乐山大佛等;而后者是指检索一个类别的图形,如塔、佛像,至于到底是哪个塔以及哪个佛像不加区分。至于为何视觉定位任务中使用实例级别图像,原因是显而易见的,因为检索到图像之后,我们就可以大致清楚拍摄查询图像的相机可能与拍摄检索图像的相机的位姿是比较接近的,可以获得一个非常粗暴的定位结果,或者查询图像要与检索到的图像进行局部特征级的匹配并进行位姿解算得到精细化的位姿,从这个意义上讲非实例级的匹配是没有意义的。
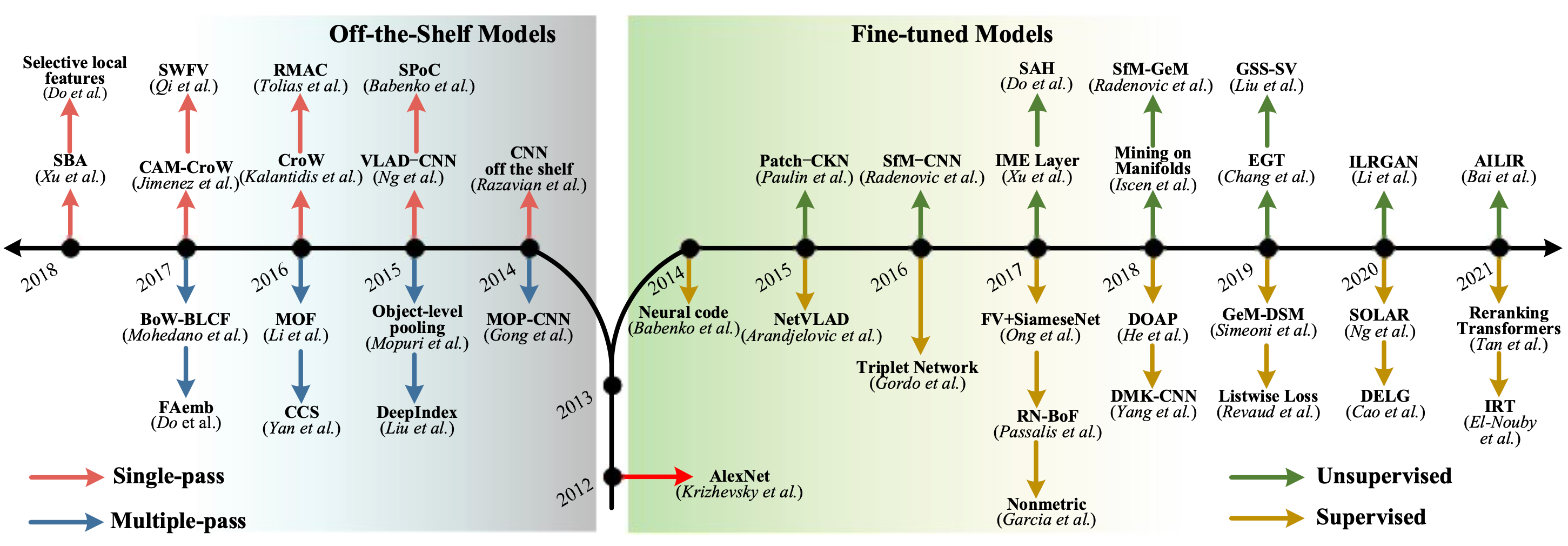
接下来详细对目前图像检索策略进行介绍,上图展示了IIR的发展脉络。整体而言,目前基于深度学习的IIR方法可以分为Off-the-shelf models(网络参数固定)以及Fine-tuned Models(网络参数调整)两个领域(后文进行简介),各自领域内衍生出诸多具有代表性的算法。例如,off-the shelf models中MAC系列(MAC/R-MAC等),fine-tuned models中的NetVLAD,DELG,HOW等。IIR的趋势在fine-tined models方向发展,主干网络从传统的CNN网络转向Transformer,注意力机制可进一步提升网络性能,面向大规模图像召回任务的无监督学习将会成为以后的主流。
自从2012年 AlexNet问世以来,深度学习便在各研究方向进行探索,迄今为止,不少于百篇在IIR领域的优秀研究工作纷纷涌现。值得说明的是,虽然论文中的方法很多,但其大体上可以总结为如下图像召回流程。
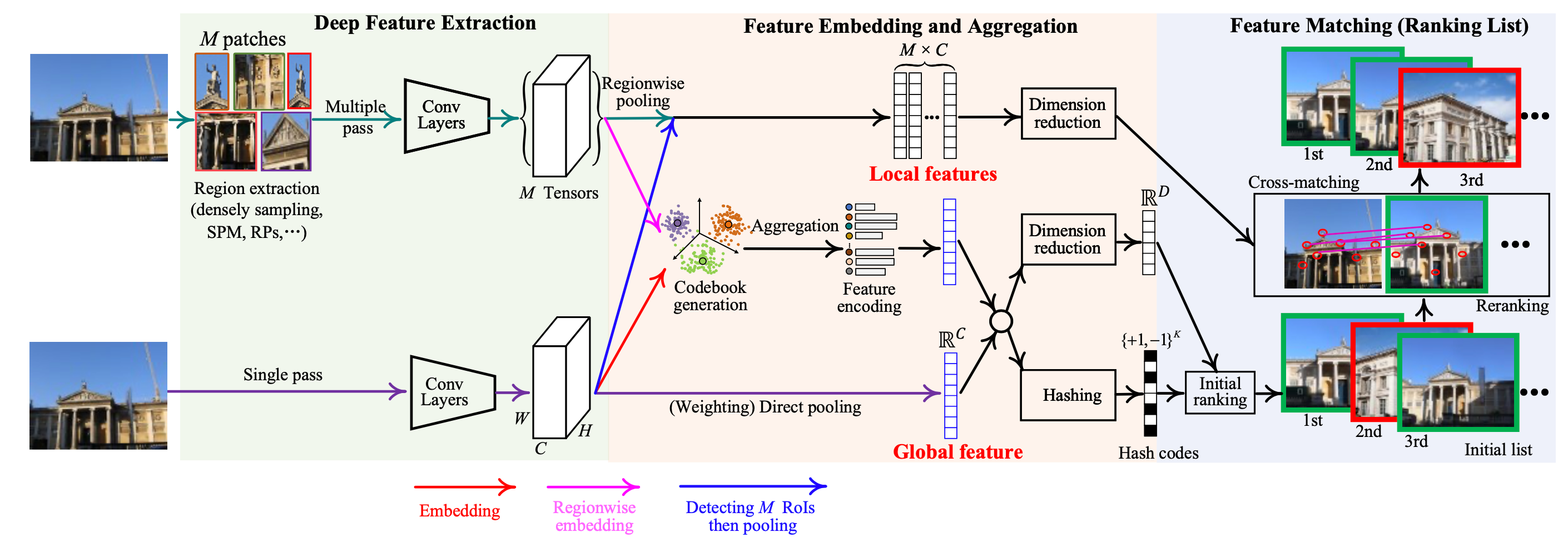
整体上看,图像召回任务可以分为三个主要步骤:深度特征提取(deep feature extraction)、特征嵌入与聚合(Feature Embedding and Aggregation)以及特征匹配(Feature Matching)或者叫做候选重排序(Re-ranking)
- 深度特征提取
该步骤主要利用神经网络强大的特征提取能力提取图像的特征,将RGB/灰度图映射为一个多维张量。此处的网络可以直接在原始图像上提取特征,这种方式称为single-pass feedforward;也可以在原始图像的patches上进行提取,此处涉及多种如上图所示的patches的设计方式,这种方式称为multi-pass feedforward。常用的特征提取网络(作为backbone)有AlexNet, VGGNet,GoogLeNet,ResNet等。
对于single-pass feedforward,网络的输入是一张图像,输出是一个高维张量 $C×H×W$ ,若将 $H$ 和 $W$ 维度展开,可得到$C\times(H \times W)$,即 $C$ 个长度为 $H×W$ 的向量;
对于multi-pass feedforward,网络的输入是M个patches,输出是M个高维张量集合;
值得说明的是,这里的特征提取网络根据其权重是否进行调整可以分划分为无参数调整网络(off-the-shelf models)以及参数调整网络(fine-tune models)。
- 特征嵌入与聚合
该步骤主要目的是进一步提升特征的可辨别性以及获得最终的全局或者局部特征。
如选定特征嵌入方式为BoW,对于single-pass feedforward的输出的数据特征根据预先训练好的字典可以分配到 $K$ 个类别,之后统计每个类别出现的频次构建基于词袋的全局特征;我们将这个过程公式化,令局部特征为 $X = { x_1, x_2, x_3, x_T}$ ,字典(或者码本)为 $C = { c_1,c_2, c_3, c_K}$ ,则每个聚类中心的聚合特征为 $g(c_k) = \frac{1}{T} \Sigma_{t = 1}^{T}$ ,则全局描述子为所有类别中数量的集合: $G_{bow} = [g(c_1), g(c_2), g(c_3), g(c_K)]$,其维度为 $K$ 。对于VLAD,只是在计算的 产生了差异,VLAD统计了局部特征距离聚类中心的$L1$距离(计算残差),将类内特征的所有残差累加并归一化得到 ,所有的类别 组合起来得到 ,维度为 $D×K$ ,其中 $D$ 为每个局部特征的维度, $K$ 为聚类类别数量。
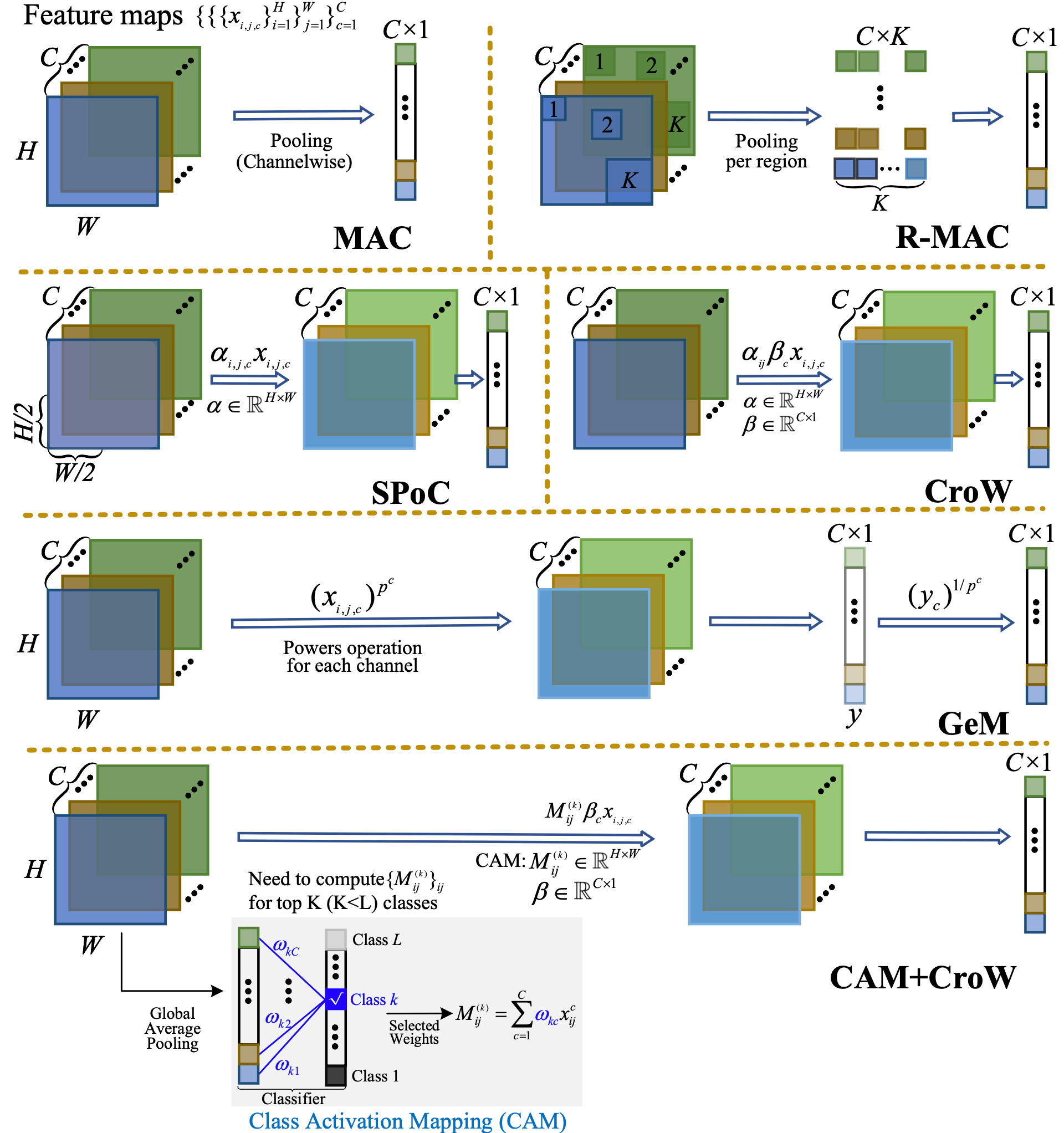
上图展示了如何将网络得到高维特征图转换成一维向量的过程。以 GeM 41为例,其具体形式如下表示:
\[\mathbf{f}^{(g)}=\left[\mathrm{f}_1^{(g)} \ldots \mathrm{f}_k^{(g)} \ldots \mathrm{f}_K^{(g)}\right]^{\top}, \quad \mathrm{f}_k^{(g)}=\left(\frac{1}{\left|\mathcal{X}_k\right|} \sum_{x \in \mathcal{X}_k} x^{p_k}\right)^{\frac{1}{p_k}}\]其中 $\mathbf{f}^{(g)}$ 维度为 $K \times 1$, $\mathcal{X}_k$ 表示第 $k \in [1,C]$ 层特征图, $p_k$ 表示常量系数( $p$ 范数),不同的 $p$ 会导致网络关注区域的差异,下图展示了这种差异。

此外,注意力机制可以被视作一种特征聚合,核心在于使用attention map强调最为相关的特征。而注意力机制中根据得到注意力图的差异可以分为无参数(non-parametric下图ab)与有参数注意力(parametric下图cd)。
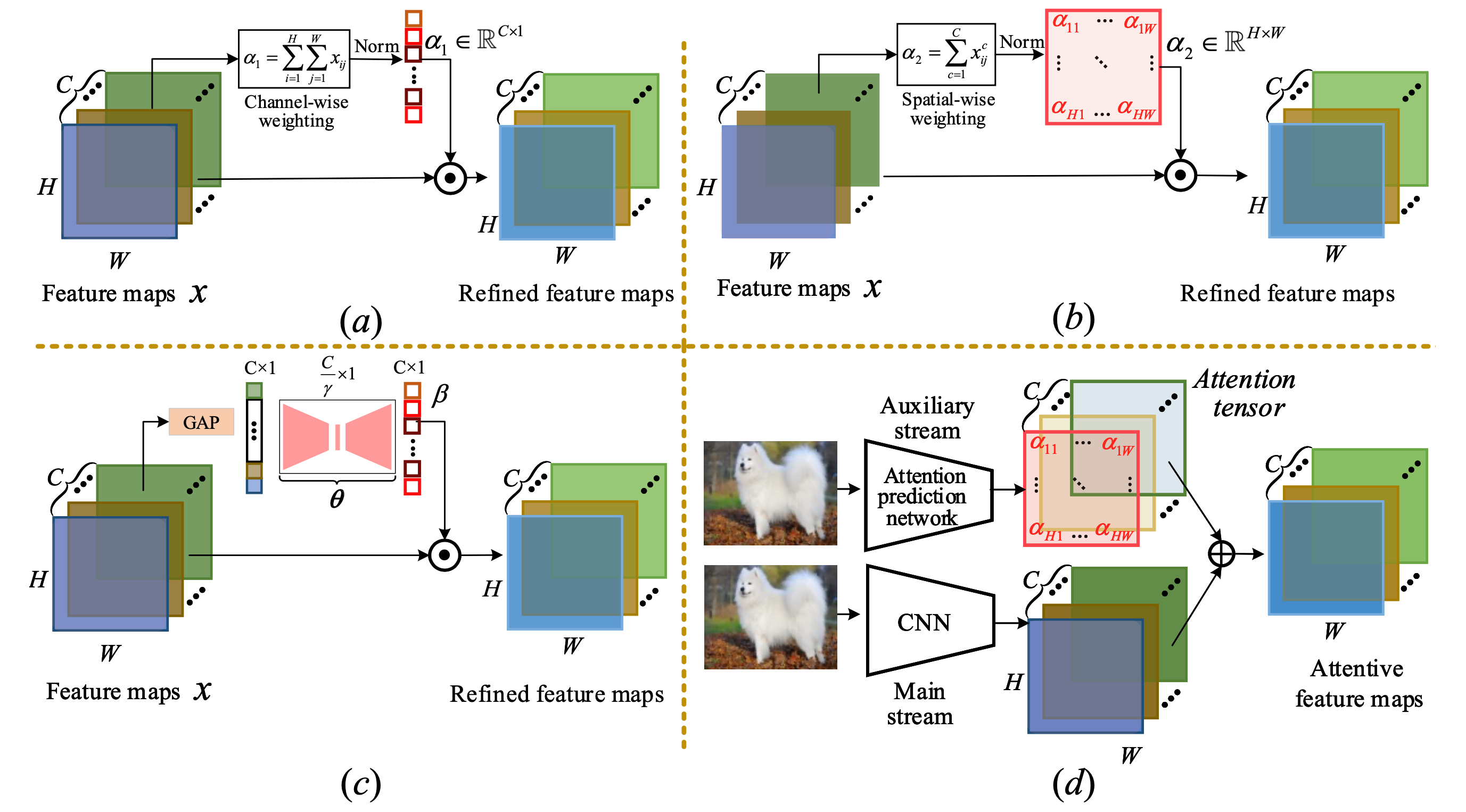
对于无参数的注意力,这种注意力机制较为直接地使用了DCNN输出层的feature maps,随后采用channel-wise(上图a)或者spatial-wise pooling(上图b)得到attention vector或者attention map; 对于有参数的注意力,通过网络学习得到注意力向量(上图c)或者注意力图(上图d)。 对于特征嵌入,hashing提供了一种新的思路,它可以将冗长的深度学习特征变换为紧凑的数据表示形式,这对于全局召回任务非常友好。
- 特征匹配/候选重排序 得到图像的全局或者局部描述之后,需要找到其在database中对应的match-lists。对于全局特征,可以使用欧氏距离、汉明距离或者其他距离度量对全局特征的相似度进行度量。对于局部特征,可以使用特征匹配+RANSAC或者ASMK的方式判定相似度。通常情况下,为了提升效率,首先使用全局描述子获得候选的match-lists之后,再使用re-ranking调整lists。
参考两篇综述文章:
BoW
VLAD
NetVLAD
http://cmp.felk.cvut.cz/cnnimageretrieval/
ASMK
TODO 待补充
首先一张图像可以被表述 $N$ 个 $d$ 维向量 $\mathcal{X} \in \mathbb{R}^d$ ,通常情况下 $N$ 的数量较大,这些描述子可以被一个“量化器”进行压缩。此处的量化器通常是一个K-MEANS无监督聚类器 $q: \mathbb{R}^d \rightarrow \mathcal{C} \subset \mathbb{R}^d$ ,其中 $\mathcal{C}=\left{\mathbf{c}1, \ldots, \mathbf{c}_k\right}$ 表示聚类中心, $c_i$ 表示某个聚类中心,也可以称为单词,有共有 $k$ 个( $k < N$ )。量化的过程可以被描述为:每个局部描述子被分配到距离其最近的聚类中心,然后可以得到已经被分配好的集合 $\mathcal{X}_c={x \in \mathcal{X}: q(x)=\mathbf{c}}$ ,它表示 $\mathcal{X}$ 中某个描述子属于 $c$ 单词,$\mathcal{C}{\mathcal{X}}$ 表示在特征 $\mathcal{X}$ 中出现的单词。定义一个二值函数 $b: \mathbb{R}^d \rightarrow{-1,1}^d$ ,$b(\mathbf{x})=\operatorname{sign}(r(\mathbf{x}))$ ,其中 $r(\mathbf{x})=\mathbf{x}-q(\mathbf{x})$ ,表示量化前的向量x与其聚类中心距离残差,比如 $x=[0.1,0.3,0.5,0.6,0.2],q(x)=[0.2,0.1,0.4,0.7,0.3]$ ,则 $r(x)=[-0.1,0.2,0.1,-0.1,-0.1],b(x)=[-1,1,1,-1,-1]$ 。
那么两张图像SMK相似度可以描述为如下式:
\[S_{\mathrm{SMK}}(\mathcal{X}, \mathcal{Y})=\gamma(\mathcal{X}) \gamma(\mathcal{Y}) \sum_{\mathbf{x} \in \mathcal{X}} \sum_{\mathbf{y} \in \mathcal{Y}}[q(\mathbf{x})=q(\mathbf{y})] k(b(\mathbf{x}), b(\mathbf{y}))\]其中[,]表示艾佛森括号,满足条件则为1,否则为0, $[q(\mathbf{x})=q(\mathbf{y})]$ 表示在计算SMK时仅考虑那些属于同一个单词的xy特征,即仅属于同一个单词的那些特征对于衡量相似度有作用; 表示归一化系数,另外,k(,)表示kernel function,,用于评价两个向量的相似度 ,其具体形式如下, 表示某个阈值,
\[k(b(\mathbf{x}), b(\mathbf{y}))=\left\{\begin{aligned} \left(\frac{b(\mathbf{x})^{\top} b(\mathbf{y})}{d}\right)^{\alpha}, & \frac{b(\mathbf{x})^{\top} b(\mathbf{y})}{d} \geq \tau \\ 0, & \text { otherwise } \end{aligned}\right.\]因此,SMK的计算等价于如下式:
通过上式可以看到,计算两张图像SMK时候需要选择相同单词的局部特征计算cross-matching score,这个过程计算量略大。而ASMK首先对局部的特征进行聚合(aggregate),然后才进行计算相似度。其中的聚合是指,将属于同一个单词的残差加和,然后再去取符号函数,这个过程可由下式描述:
\[B\left(\mathcal{X}_c\right)=\operatorname{sign}\left(\sum_{x \in \mathcal{X}_c} r(\mathbf{x})\right)\]其中 ,那么ASMK的计算可以描述为下式:
\[S_{\text {ASMK }}(\mathcal{X}, \mathcal{Y})=\gamma(\mathcal{X}) \gamma(\mathcal{Y}) \sum_{c \in \mathcal{C}_{\mathcal{X}} \cap c_{\mathcal{Y}}} k\left(B\left(\mathcal{X}_c\right), B\left(\mathcal{Y}_c\right)\right)\]从上式可以看出ASMK相似度是对属于同一单词的聚合后的特征使用kernel函数计算相似度。此外,计算ASMK相比SMK具有更高的效率以及可应对burstiness phenomenon(即重复纹理对图像召回的干扰)。
DELF & DELG
基于位姿回归的方案(Pose regression-based)
最近,随着深度学习在图像分类,语义分割,图像召回以及其他视觉任务的成功应用,那么基于深度学习的视觉定位也成为了可能。方式比较粗暴,输入一张RGB图像,网络端到端回归出拍摄这张图像的相机位姿。基于low level特征可用于一些较为通用的视觉任务(如图像分类)的假设,一些研究者认为这些特征中同样也encode着位姿的某些信息,所以他们建议使用预训练模型通过迁移学习的的方式进行位姿估计任务。
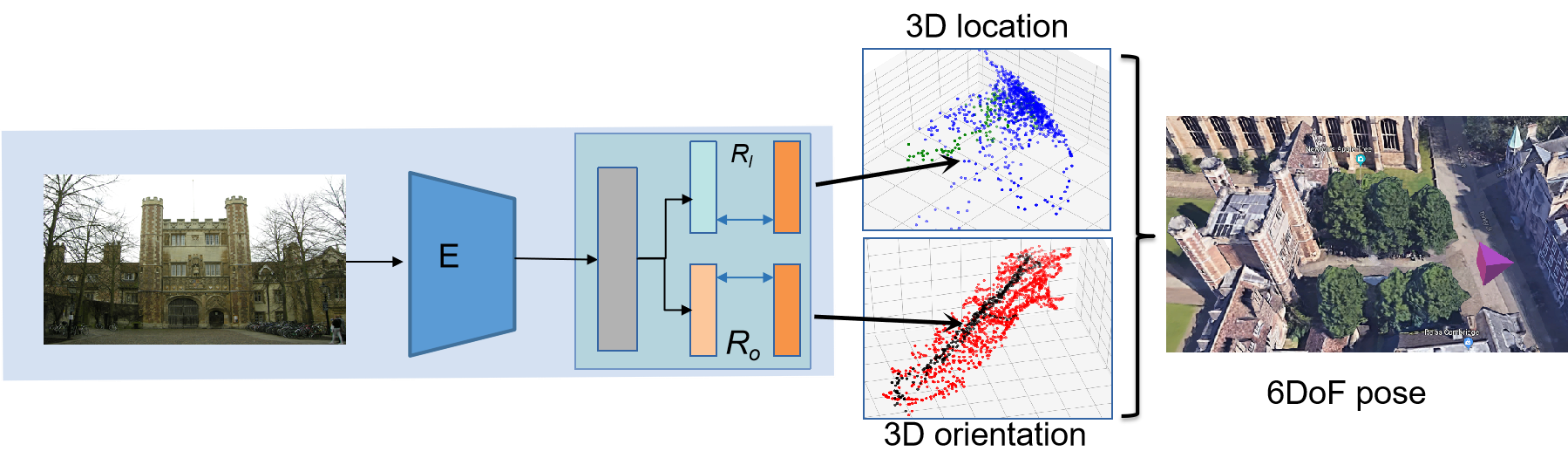
例如,大名鼎鼎的 PoseNet42 修改了分类任务CNN网络结构的任务头,如将VGG/GoogLenet/ResNet的softmax层替换成全联接(FC)层。如上图所示,网络对平移量与旋转量分别进行回归。
PoseNet42 是 Alex 等人于2015年发表在ICCV上的文章,本文首次将CNN引入对位姿的学习,即将位姿估计问题建模成一个回归问题(regression),能够在室内外实现相机定位,如在室外约50000平米达到2m/6deg以及室内0.5m/10deg的定位效果。
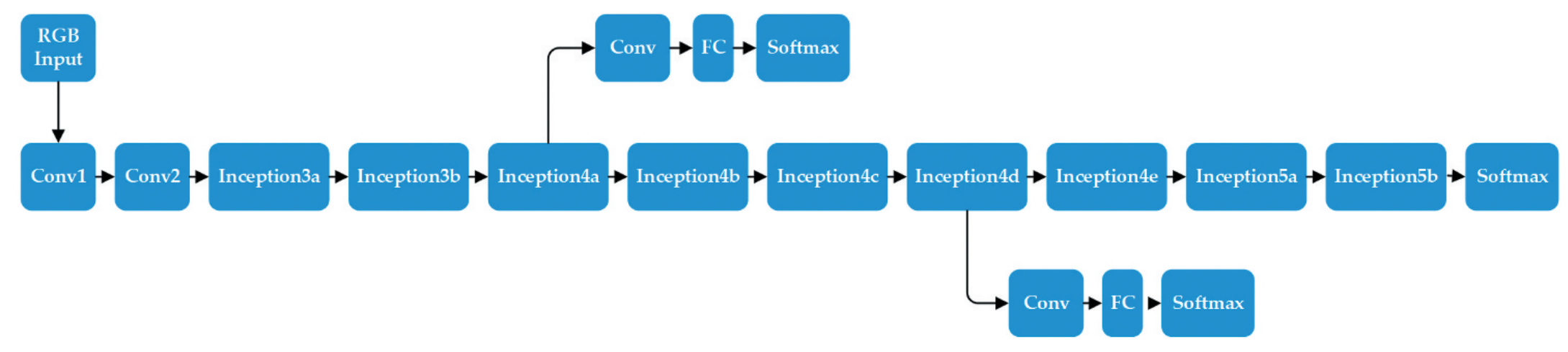
其网络结构较简单,是基于GoogLenet进行的修改,原始的GoogLenet输入是224*224的图像,之后经过5阶段(stage3-5分别有2/5/2个inception模块,共有9个),最后接FC+softmax用于预测类别(除此之外,还有两个中间层临时预测头)。PoseNet相较于GoogLenet有如下改进(代码见此处):
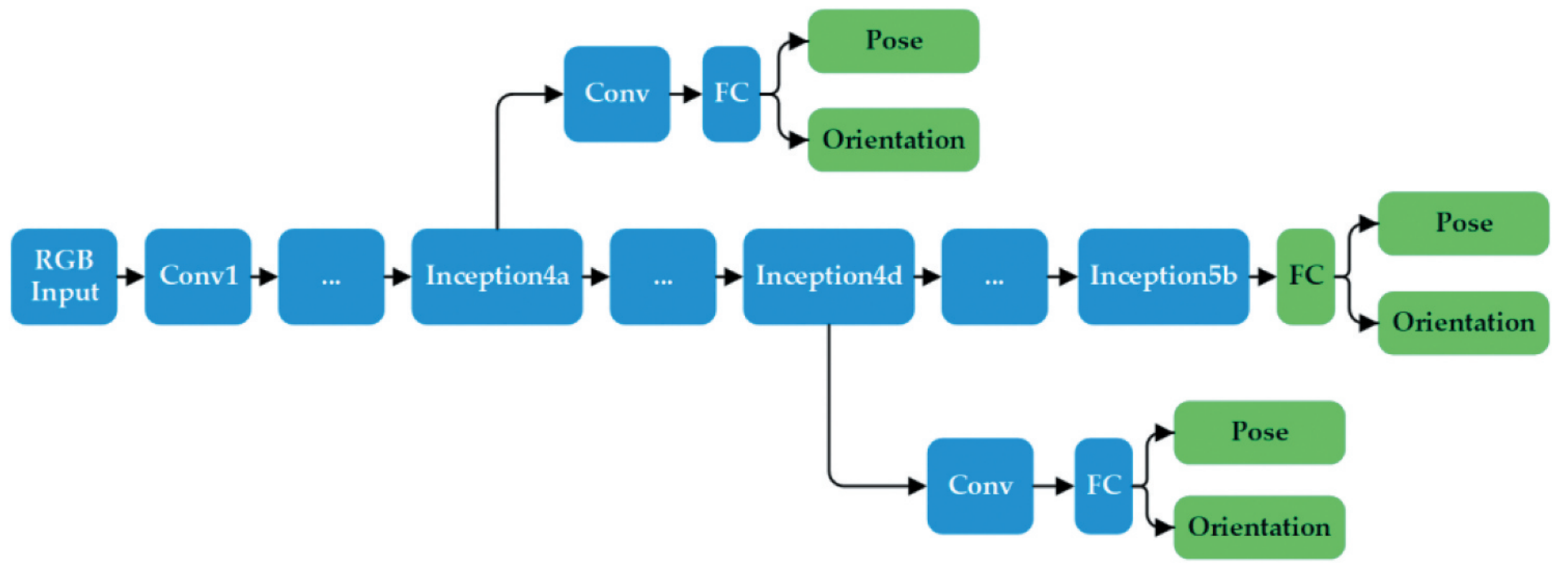
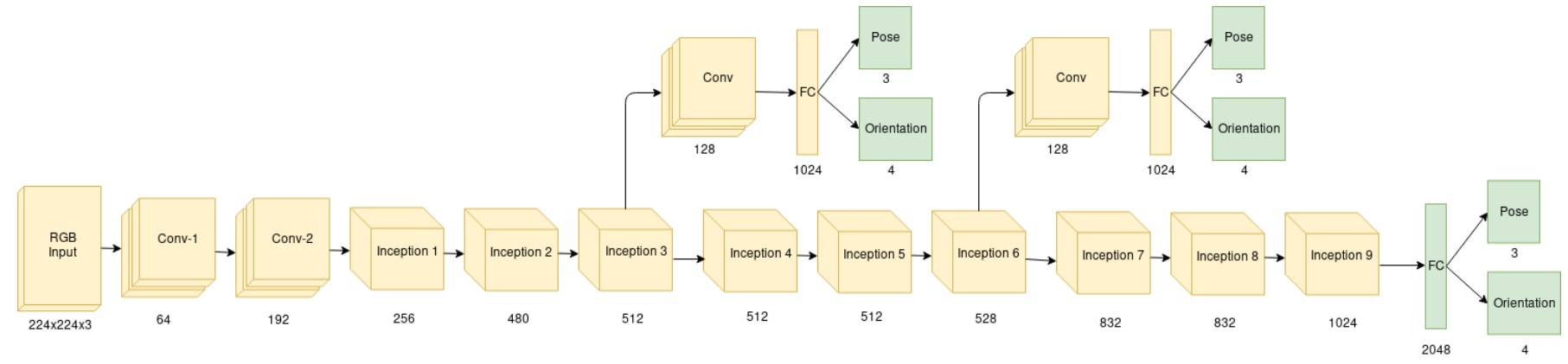
- 使用位姿回归器代替原来的3个softmax分类器,即移除softmax,最后层改为全连接层,输出位置矢量(3维)和四元数方向矢量(4维)的7维pose矢量;
- 在最终的回归器前插入一个长度为2048的全连接,目的是为了增强位姿回归的泛化性(但实际上并不好);
- 测试时需要对估计的四元数进行归一化;
损失函数非常简单:
\[\operatorname{loss}(I)=\|\hat{\mathbf{x}}-\mathbf{x}\|_2+\beta\left\|\hat{\mathbf{q}}-\frac{\mathbf{q}}{\|\mathbf{q}\|}\right\|_2\]其中 $\beta$ 为尺度系数用于调整平移量与旋转量损失的权衡,如室外条件下比室内的平移量大,所以 $\beta$ 室外会比室内大,具体的,室内120-750,室外250-2000。
直接通过端到端的方式的进行绝对位姿回归的拥有诸多益处。首先,位姿回归并不需要复杂的特征工程,它仅依赖于深度网络的强大的编码能力,能够有效应对光照变化以及视角变化。其次,与基于3D特征的定位方法相比,位姿回归需要更小的内存并且拥有常数级的推理时间(查询图像尺寸固定,如PoseNet推理耗时仅为5ms,权重大小仅为50MB)。最后,迁移学习能够使得网络能在中等规模数据集中高效训练。但是,PoseNet精度低是硬伤,相比于基于3D结构信息定位的方式的误差大了一个数量级。
为降低定位误差,一些算法针对PoseNet存在的问题进行改进,如使用新的损失函数38, 新增长短期记忆层(LSTM),新增数据集或者信息其他传感器观测43等。为了进一步提升性能,VLocNet44提出了一种同时学习绝对位姿以及相对位姿的算法, VLocNet++45通过语义分割辅助进一步的提升精度。
然而,端到端的学习位姿通常会使结果陷入局部最优,因为它与场景坐标紧密耦合,网络可以看作是地图(场景)的一种压缩,并不具备泛化能力。
Satter等人于2019年发表在CVPR上的工作32解释了相机定位任务中位姿回归问题的局限性:位姿回归相较于基于结构信息定位的算法精度低很多,作者设计了一个理论模型用于解释位姿回归中的failure cases。此外,这项工作得到几个结论:
- 目前位姿回归算法于直接进行召回top k相机位姿加权平均精度相当;
- 目前所有的位姿回归算法都无法保证具备泛化性(在其训练集以外);
- 随着训练集数量的增多,位姿回归的精度越高;
作者认为位姿回归可以建模成3个阶段:阶段一,特征提取 $F(\mathcal{I})$ ,即使用某个主干网络对图像提取高维特征;阶段二,(非线性)特征嵌入 $E(F(\mathcal{I}))$ ,将阶段一得到的高维特征映射到成某长度为 $n$ 的向量 $\alpha^{\mathcal{I}}=\left(\alpha_1^{\mathcal{I}}, \ldots, \alpha_n^{\mathcal{I}}\right)^T \in \mathbb{R}^n$ ,该过程通常位于位姿回归器前一步;阶段三,通过线性映射将嵌入的特征投影到相机位姿空间,这个阶段即使用全连接层进行实现;所以相机位姿的估计量可以描述为下式:
\[\begin{aligned} L(\mathcal{I}) &=\mathbf{b}+\mathbf{P} \cdot E(F(\mathcal{I})) \\ &=\mathbf{b}+\mathbf{P} \cdot\left(\alpha_1^{\mathcal{I}}, \ldots, \alpha_n^{\mathcal{I}}\right)^T \end{aligned}\]其中 $\mathrm{P} \in \mathbb{R}^{(3+r) \times n}$ 表示最后的线性投影矩阵,维度为 $(3+r) \times n$ , $\mathbf{b} \in \mathbb{R}^{3+r}$ 表示偏置量; $L(\mathcal{I})$ 就是相机位姿 $\hat{\mathbf{p}}{\mathcal{I}} = \left(\hat{\mathbf{c}}{\mathcal{I}},\hat{\mathbf{r}}_{\mathcal{I}}\right)$ 的估计量。
经过推导,相机位姿的估计量可以由下式表示,其中 $\mathbf{P}_j = (\mathbf{c}_j^T,\mathbf{r}_j^T)^T$ 表示投影矩阵 $\mathrm{P}$ 的第 $j$ 列向量, 偏置量为 $\mathbf{b} = (\mathbf{c}_b^T,\mathbf{r}_b^T)^T$ 。
\[\left(\begin{array}{l} \hat{\mathbf{c}}_{\mathcal{I}} \\ \hat{\mathbf{r}}_{\mathcal{I}} \end{array}\right)=\left(\begin{array}{l} \mathbf{c}_b+\sum_{j=1}^n \alpha_j^{\mathcal{I}} \mathbf{c}_j \\ \mathbf{r}_b+\sum_{j=1}^n \alpha_j^{\mathcal{I}} \mathbf{r}_j \end{array}\right)\]通过上式我们可以发现,相机位姿回归可以描述为:通过诸如 PoseNet 或者其变体可以学习到一系列的基础位姿 $\mathcal{B}=\{(\mathbf{c}_j,\mathbf{r}_j)\}$ ,这样训练集可以表示为这些基础位姿的线性叠加。第二个阶段得到的嵌入后的向量决定了位姿加权权重。
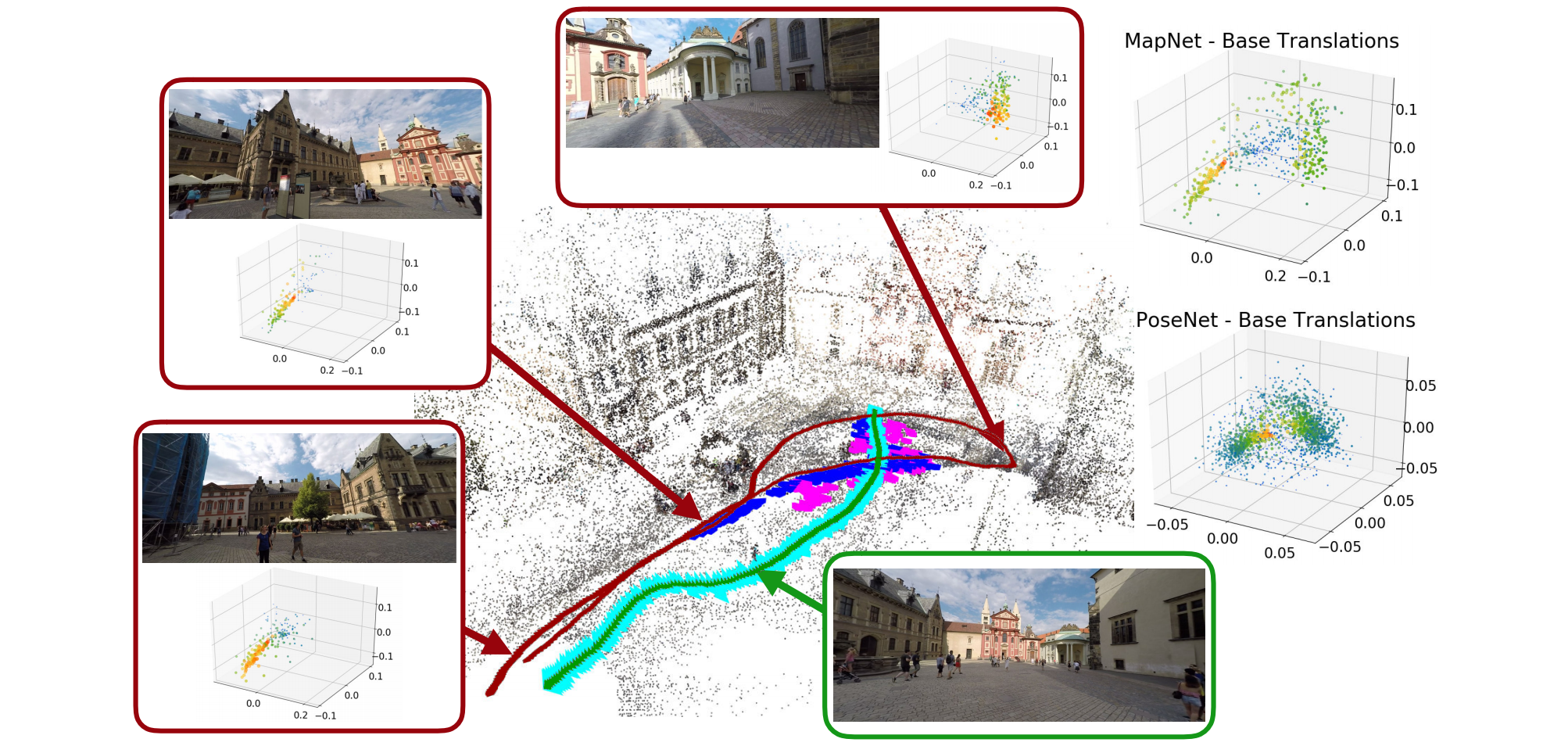
上图展示了分别使用PoseNet以及MapNet得到的基础平移量的分布图(分别有每张训练图以及全部图像的分布),颜色越暖,点size越大表示权重越大。其中深红色表示训练集,绿色表示测试集,PoseNet/MapNet以及ActiveSearch(基线)的预测结果分别用蓝色/紫色以及青色表示;
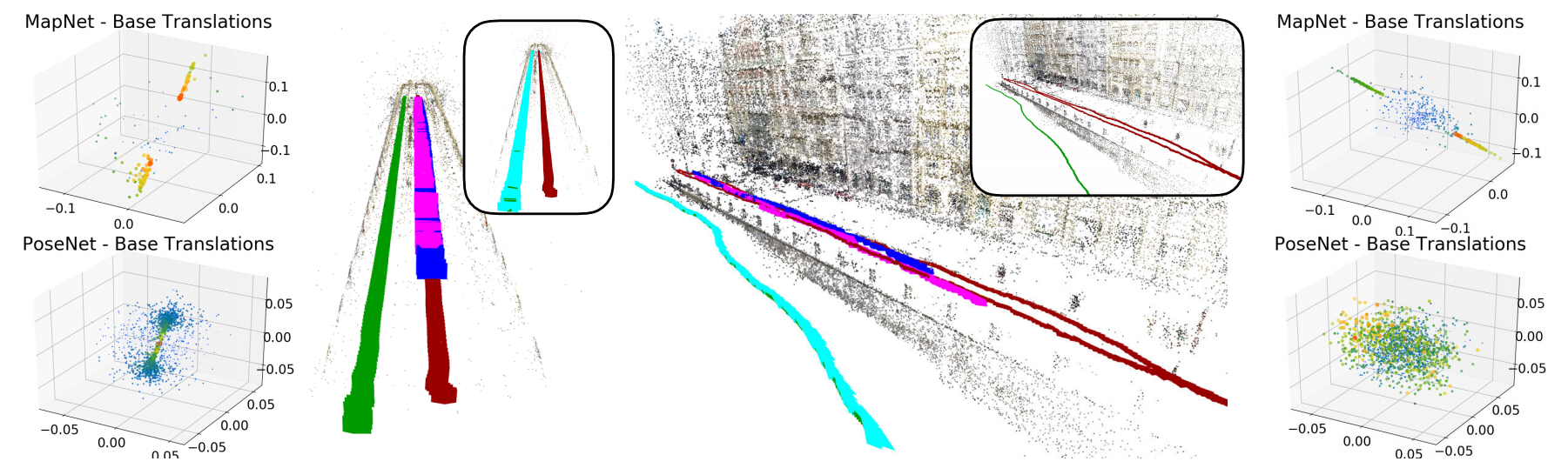
上图展示当训练集为直线段时位姿回归的结果,可见位姿回归的位姿的全部位于训练集附近,而距离测试集较远。下图展示了更为一般的测试场景,结果与上述结论一致,即位姿回归的结果无法泛化到训练集无法覆盖的区域。
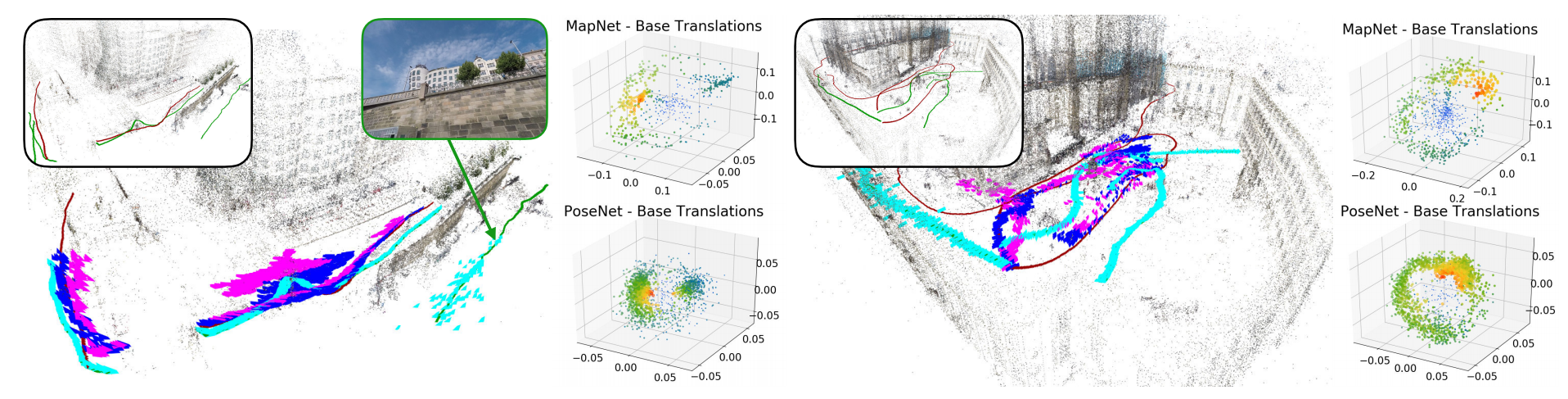
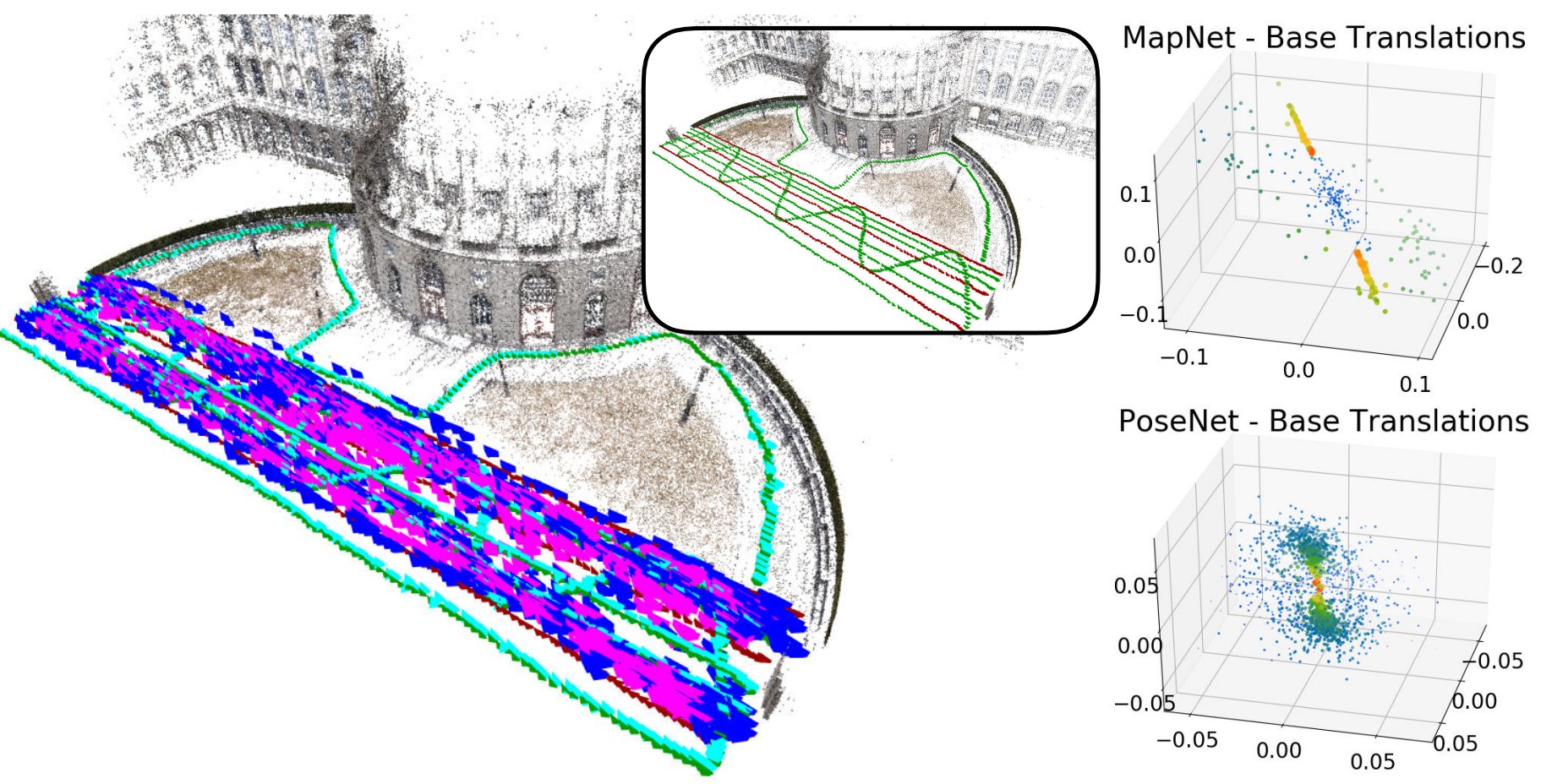
关于上述测试更为直观的介绍参考附录中提到的视频。
目前也有一些混合位姿估计算法将学习的目标转向视觉定位中的某个环节,而非使用端到端的方式,并将其与传统的图像检索和基于结构信息定位的算法结合。例如DSAC46 集合约束,它的目标聚焦在局部的视觉任务中,如2D-3D数据关联。虽然这种方式可以较大幅度提升位姿精度,但学习的模型仍然是场景相关的,并不具备泛化能力。为了提升泛化能力,SANet47提出了一种场景无关的视觉定位算法,该模型利用图像召回 top k 图像稠密MVS获得的三维点云的几何结构进行相机位姿回归。
其他
辅助位姿解算 pixloc / BANET
NeRF based
秦通博士写的这篇NeRF-base SLAM综述值得一读,其中列举了自从2020年以来nerf用于位姿估计的几篇工作,如inerf,iMAP,nice-slam等技术;
其中发表在CVPR 2022的nice-slam中提到,iMAP(Sucar et al. ICCV 2021)是首个可以实现实时工作的基于隐式表达的稠密SLAM,但其存在三个问题;
- 仅能够在小范围的室内使用,无法扩展到较大的场景;
- 面临全局更新的问题,即每一个关键帧参与优化后导致的网络参数的全数更新(forgetting problems)
- 收敛很慢
而nice-slam在一定程度上解决了上述问题,它使用了一种多层次grid-based场景表示方式对3D点进行描述,使用volume rending的方式渲染出深度图以及RGB图像用于建图与追踪。
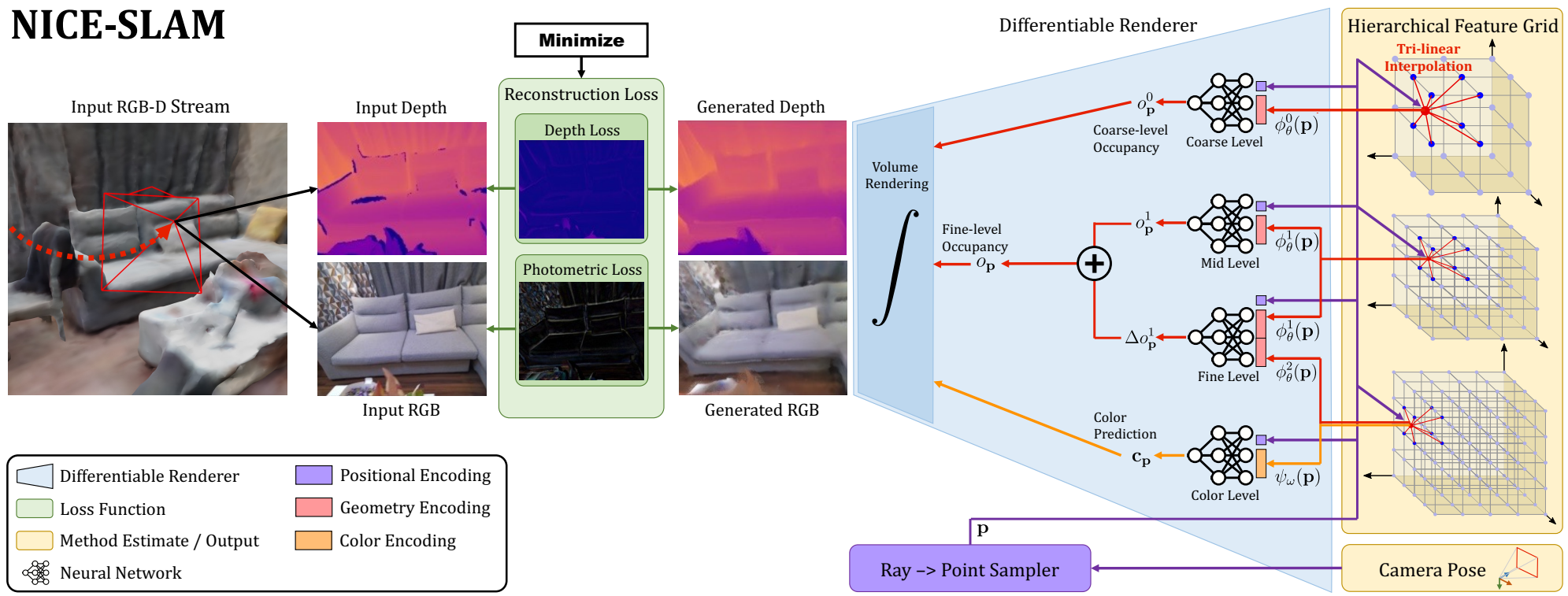
上图展示的nice-slam的工作流程。系统的输入是RGBD信息,输出是相机位姿以及经过学习的场景表示(即hierarchical feature grid)。从右向左看,上图中的流程可以被描述为一个给定相机位姿以及场景表示,输出RGB以及深度图的过程。在测试阶段(从左向右看),网络同时估计场景表示以及相机位姿,这个过程是通过求解构建RGB以及depth时产生的重建loss的逆问题完成;且每次仅完成一项工作,比如,Mapping:反向传播过程仅更新场景表示;Tracking:反向传播仅更新相机位姿。
场景表示分为:geometry(几何信息,即深度图或3D点)以及 appearance(外观表示,即RGB图),所谓的多层次的场景表示是针对geometry表示而言,nice-slam将其设计为3个不同尺度(coarse,mid以及fine-level)的feature-grids极其对应的MLP解码器(这里提到的解码是将grid中的3D点编码后的信息解码成Depth,这与NeRF中MLP要做的事情完全一致,只不过换了一种称呼)。此外,对于场景的外观表示,有一个单独的feature-grid以及对应的MLP解码器(接在fine-level)。
对于几何表示,首先介绍在mid&fine-level对其进行表征的形式,对于每个3D点 $\mathbf{p} \in \mathbb{R}^3$ 通过空间三线性插值得到其编码feature,随后将其喂给MLP,输出对应的 occupancy $o_{\mathbf{p}}^1$ ;fine-level作为对细节的补充,其解码器学习的是相对于coarse-level的offset:$\Delta o_{\mathbf{p}}^1$,完整的occupancy 可以表示为上述二者相加:
\[o_{\mathbf{p}} = o_{\mathbf{p}}^1 + \Delta o_{\mathbf{p}}^1\]有了从mid&fine-level得到的occ后,我们也可以从coarse-grid得到一些关于场景的high-level信息,coarse-grid可以预测出occ大致的信息,作者提到粗尺度的信息可以捕获中/精尺度没有观测的信息,应对追踪过程中lost问题。
Mapping以及tracking过程中需要更新场景表示的参数以及MLP参数,损失函数分为geometric loss(粗深度以及精深度重建L1损失)以及photometric loss(RGB图像重建L1损失)
TODO(补充更多nice-slam细节)
结论展望
- 最近的基准测试和定位挑战结果表明,基于几何的方法仍然优于端到端方法。然而,值得注意的是,为了达到最佳性能,纯几何学流程中的几个模块被深度学习的方案所取代,如局部和全局特征提取。事实上,基于深度网络的表征比手工制作的特征更有优势,能够较好地应对各种变化;
- 当我们的目的只是为了获得一个粗略的位置时,存粹的基于图像召回(检索)的方式是一个低成本的解决方案,例如
geo-localization; - 当三维模型或点云都不可用时,位姿回归的方式仍然有效;
- 为了应对的视觉定位中的挑战,使用场景的语义信息(物体、建筑或景观)是一种较好的手段。例如,人们可以使用语义类别(如树、建筑、街道)来改善局部特征的匹配48 49,或者使用物体进行定位50 51 52。Weinzaepfel等人53提出建立一个感兴趣区域物体的数据库,并直接回归查询图像中检测到的物体与它们在三维空间表征的局部特征匹配。由于汽车、人甚至树木等动态区域给视觉定位带来了挑战,人们也可以在视觉定位中忽略这些区域9 3;
- 此外,未来方向还包括:改进局部和全局特征,利用多相机系统和图像序列,以及为绝对和相对相机姿势回归增加更好的泛化能力。
参考
-
Laurent Kneip, Davide Scaramuzza, and Roland Siegwart. A Novel Parametrization of the Perspective-three-point Problem for a Direct Computation of Absolute Camera Position and Orientation. In CVPR, 2011. ↩ ↩2
-
T. Sattler, B. Leibe, and L. Kobbelt. Fast image-based localization using direct 2d-to-3d matching. In ICCV, 2011. ↩
-
Pierre Moulon, Pascal Monasse, and Renaud Marlet. Global Fusion of Relative Motions for Robust, Accurate and Scalable Structure from Motion. In ICCV, 2013. ↩ ↩2 ↩3
-
Torsten Sattler, Bastian Leibe, and Leif Kobbelt. Efficient & Effective Prioritized Matching for Large-Scale Image-Based Localization. PAMI, 39(9):1744–1756, 2017. ↩
-
Liu Liu, Hongdong Li, and Yuchao Dai. Efficient Global 2D-3D Matching for CameraLocalization in a Large-Scale 3D Map. In ICCV, 2017. ↩
-
H. Taira, M. Okutomi, T. Sattler, M. Cimpoi, M. Pollefeys, J. Sivic, T. Pajdla, and A. Torii. InLoc: Indoor Visual Localization with Dense Matching and View Synthesis. PAMI, 2019. ↩
-
Johannes L. Schonberger and Jan-Michael Frahm. Structure-from-motion Revisited. In CVPR, 2016. ↩ ↩2 ↩3
-
Gabriela Csurka, Christopher R. Dance, and Martin Humenberger. From Handcrafted to Deep Local Invariant Features. arXiv, 1807.10254, 2018. ↩ ↩2
-
Revaud Jerome, Philippe Weinzaepfel, Cesar De Souza, and Martin Humenberger.R2D2: Reliable and Repeatable Detectors and Descriptors. In NeurIPS, 2019. ↩ ↩2 ↩3
-
David G. Lowe. Distinctive Image Features from Scale-invariant Keypoints. IJCV, 60(2):91–110, 2004. ↩
-
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-Net: a Trainable CNN for Joint Description and Detection of Local Features. In CVPR, 2019. ↩
-
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperPoint: Self-Supervised Interest Point Detection and Description. In CVPR Workshops, 2018. ↩
-
Axel Barroso-Laguna, Edgar Riba, Daniel Ponsa, Krystian Mikolajczyk. Key.Net: Keypoint detection by handcrafted and learned cnn filters. ICCV 2019. PDF, Code ↩
-
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: Learning Feature Matching with Graph Neural Networks. In CVPR, 2020. ↩
-
Johannes Lutz Schonberger, Hans Hardmeier, Torsten Sattler, and Marc Pollefeys. Comparative Evaluation of Hand-Crafted and Learned Local Features. In CVPR, 2017. ↩
-
Ma Jiayi et.al. Image Matching from Handcrafted to Deep Features: A Survey. International Journal of Computer Vision (IJCV 2020) ↩
-
M. Fischler and R. Bolles. Random Sampling Consensus: A Paradigm for Model Fitting with Application to Image Analysis and Automated Cartography. Communications of the ACM, 24:381–395, 1981. ↩
-
O. Chum and J. Matas. Optimal Randomized RANSAC. PAMI, 30(8):1472 –1482, 2008. ↩
-
Barath Daniel, Matas Jiri, Noskova Jana. MAGSAC: marginalizing sample consensus, CVPR 2019. ↩
-
Barath Daniel, Noskova Jana, Ivashechkin Maksym, Matas Jiri. MAGSAC++: a fast, reliable and accurate robust estimator, CVPR 2020. ↩
-
Torsten Sattler, Will Maddern, Carl Toft, Akihiko Torii, Lars Hammarstrand, Erik Stenborg, Daniel Safari, Masatoshi Okutomi, Marc Pollefeys, Josef Sivic, Fredrik Kahl, and Tomas Pajdla. Benchmarking 6DoF Outdoor Visual Localization in Changing Conditions. In CVPR, 2018. ↩
-
Sattler, Torsten, Bastian Leibe, and Leif Kobbelt. Improving image-based localization by active correspondence search. ECCV 2012. PDF ↩
-
Image-Based Localization, https://www.graphics.rwth-aachen.de/software/image-localization ↩
-
Martin Humenberger, Yohann Cabon, Nicolas Guerin, Julien Morat, Jerome Revaud, Philippe Rerole, Noe Pion, Cesar de Souza, Vincent Leroy, and Gabriela Csurka. Robust Image Retrieval-based Visual Localization using Kapture. arXiv:2007.13867, 2020. ↩
-
Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. From Coarse to Fine: Robust Hierarchical Localization at Large Scale. In CVPR, 2019. ↩
-
Eric Brachmann and Carsten Rother. Learning less is more – 6d camera localization via 3d surface regression. In CVPR, 2018. ↩
-
Eric Brachmann and Carsten Rother. Expert sample consensus applied to camera re-localization. In ICCV, 2019. ↩
-
Xiaotian Li, Shuzhe Wang, Yi Zhao, Jakob Verbeek, and Juho Kannala. Hierarchical scene coordinate classification and regression for visual localization. In CVPR, 2020. ↩
-
Eric Brachmann and Carsten Rother. Visual camera re-localization from rgb and rgb-d images using dsac, arXiv, 2020. ↩
-
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene Coordinate Regression Forests for Camera Relocalization in RGB-D Images. In CVPR, 2013. ↩
-
Akihiko Torii, Josef Sivic, and Tomas Pajdla. Visual Localization by Linear Combination of Image Descriptors. In ICCV Workshops , 2011. ↩
-
Torsten Sattler, Qunjie Zhou, Marc Pollefeys, and Laura Leal-Taixe. Understanding the Limitations of CNN-based Absolute Camera Pose Regression. In CVPR, 2019. ↩ ↩2
-
Wei Zhang and Jana Kosecka. Image Based Localization in Urban Environments. In 3DPVT, 2006. ↩
-
Qunjie Zhou, Torsten Sattler, Marc Pollefeys, and Laura Leal-Taixe. To Learn or not to Learn: Visual Localization from Essential Matrices. ICRA, 2020. ↩
-
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In CVPR, 2016. ↩
-
Akihiko Torii, Relja Arandjelovic, Josef Sivic, Masatoshi Okutomi, and Tomas Pajdla. 24/7 Place Recognition by View Synthesis. In CVPR, 2015. ↩
-
Albert Gordo, Jon Almazan, Jerome Revaud, and Diane Larlus. End-to-End Learning of Deep Visual Representations for Image Retrieval. IJCV, 124:237—-254, 2017. ↩
-
Alex Kendall and Roberto Cipolla. Geometric Loss Functions for Camera Pose Regression with Deep Learning. In CVPR, 2017. ↩ ↩2
-
Jerome Revaud, Jon Almazan, Rafael Sampaio de Rezende, and Cesar Roberto de Souza. Learning with Average Precision: Training Image Retrieval with a Listwise Loss. In ICCV, 2019. ↩
-
Noé Pion, Martin Humenberger, Gabriela Csurka, Yohann Cabon, and Torsten Sattler. Benchmarking Image Retrieval for Visual Localization. In 3DV, 2020. ↩
-
Filip Radenovic, Giorgos Tolias, and Ondrej Chum. Fine-Tuning CNN Image Retrieval with no Human Annotation. PAMI, 41(7):1655–1668, 2019. PDF, Code ↩
-
Alex Kendall, Matthew Grimes, and Roberto Cipolla. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In ICCV, 2015. ↩ ↩2
-
Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, and Jan Kautz. Geometry aware learning of maps for camera localization. In CVPR, 2018. ↩
-
Abhinav Valada, Noha Radwan, and Wolfram Burgard. Deep auxiliary learning for visual localization and odometry. In ICRA, 2018. ↩
-
N. Radwan, A. Valada, and W. Burgard. Vlocnet++: Deep multitask learning for semantic visual localization and odometry. RA-L, 3(4):4407–4414, 2018. ↩
-
Eric Brachmann, Alexander Krull, Sebastian Nowozin, Jamie Shotton, Frank Michel, Stefan Gumhold, and Carsten Rother. DSAC – differentiable RANSAC for camera localization. In CVPR, 2017. ↩
-
Luwei Yang, Ziqian Bai, Chengzhou Tang, Honghua Li, Yasutaka Furukawa, and Ping Tan. Sanet: Scene agnostic network for camera localization. In ECCV, 2019. ↩
-
Carl Toft, Erik Stenborg, Lars Hammarstrand, Lucas Brynte, Marc Pollefeys, Torsten Sattler, and Fredrik Kahl. Semantic match consistency for long-term visual localization. In ECCV, 2018. ↩
-
Nikolay Kobyshev, Hayko Riemenschneider, and Luc Van Gool. Matching features correctly through semantic understanding. In 3DV, 2014. ↩
-
Renato F Salas-Moreno, Richard A Newcombe, Hauke Strasdat, Paul HJ Kelly, and Andrew J Davison. Slam++: Simultaneous localisation and mapping at the level of objects. In CVPR, 2013. ↩
-
Andrea Cohen, Johannes L Schonberger, Pablo Speciale, Torsten Sattler, Jan-Michael Frahm, and Marc Pollefeys. Indoor-outdoor 3d reconstruction alignment. In ECCV, 2016. ↩
-
Shervin Ardeshir, Amir Roshan Zamir, Alejandro Torroella, and Mubarak Shah. Gis-assisted object detection and geospatial localization. In ECCV, 2014. ↩
-
Philippe Weinzaepfel, Gabriela Csurka, Yohann Cabon, and Martin Humenberger. Visual localization by learning objects-of-interest dense match regression. In CVPR, June 2019. ↩